1. Acquire, Store, Analyze, and Present
With the increased number and ability of digital sensors and channels to acquire data, UCI needs a network infrastructure that is able to Acquire, Store, Analyze, and Present (ASAP) that data in a timely, secure, and easy-to-use manner.
Data is getting big. From ubiquitous smartphones sensors, to genomic sequencers, confocal microscopes, PET/CAT scanners, to national-scale image and data collectors such as satellite, census, and other government data sources, and even commercial social networking data (Google, Facebook, Twitter), research data is getting larger. With that increase in data size comes the requirement to be able to store it and process it in reasonable times. We already are changing the mechanics and protocols for high speed data within our Data Centers, but in order to support research widely, we will have to expand those mechanisms, both for storing data and moving it into and out of our Data Centers. This proposal addresses that need by directly proposing a large campus storage system, backed by the very high-speed transport needed for data replication and back-end movement of large data sets to the analysis centers and back again.
2. Campus data storage
UCI is embarking on a project to develop a campus-wide storage system that will provide redundant, geographically dispersed storage system for researchers to use for the ASAP operations noted above. The system has 2 faces; one for general researcher access that will be based on the existing, fairly slow (100Mbs-1 Gbs) campus network, and another higher speed 10-40Gbs network to allow the same underlying storage system to allow compute clusters and other specialized machinery to transfer bulk data to/from it with maximum speed.
We consider 2 types of data; the first is large, raw, unprocessed, cheap-to-reproduce data; the second is analyzed, reduced data that is worth considerably more in terms of the amount of labor used to produce it. That is: cheap, big, raw data (¢data) and expensive, small, processed data ($data). The point of research is to transform the former into the latter, with useful information extracted, concentrated, and hopefully published in the process. Publishing in this case refers to peer-reviewed journals, making the raw data available as a supplement to the journal publication, and/or archiving it for longer periods for public access. The last reference is is especially relevant since it is a state directive to the university and a requirement of many funding agencies.
In order to supply researchers with storage to process the ¢data, we have to consider very cheap, fairly reliable storage as opposed to very expensive, very reliable storage (from EMC, NetApp, DDN), since the price differential between these 2 is easily 10X or more. Since it is not the primary point of this submission, we do not describe the storage system in detail here, but it is based on the Fraunhofer Distributed file system or a similar technology and will be used to provide:
-
up to multiple Petabyte scale intermediate data store for small and large data sets
-
the data stored can simultaneously be accessed by both desktop and compute cluster tools.
-
limited backup, including geographically dispersed backup.
-
access to read-enabled directories to distribute data to the web via browser or more sophisticated tools such as Globus Connect or bbcp, as well as rsync, Filezilla, and other file tranfer protocols/clients
-
data sharing among collaborators via the above mechanisms
-
staging for submission to formal archives such as the Merrit repository of the California Digital Library
3. Very Fast, Very Large Data Transfer
While there are ways to avoid & improve some network data transfer, eventually bytes need to move, and the larger the pipe, the easier the transfer. We are now seeing unprecedented amounts of data flow in and out of UCI, especially genomic, satellite, and CERN/LHC data. In order to move that data to/from the primary analysis engines in our Data Center, we minimally need 10Gb ethernet, and preferably higher speed, lower latency mechanisms such as Long-Haul Infiniband (LHIB).
Data traversing UCI’s primary internet connection (CENIC) tends to be packaged in ways that do not require short latencies (ie they are in archives which can be streamed in large chunks). However, internal to UCI where the data tends to be unpacked into separate (often small) files, and analyzed by applications that use MPI communication, low latency is almost as important as high bandwidth in terms of moving data or files around. In this scenario, it would be better to use a technology based on LHIB instead of 10Gb ethernet.
Intra-campus, these are the bottlenecks with our present network:
-
data archives to/from the internet via CENIC (Thornton, Long, Tobias, Steele, Mortazavi, Zender, Small)
-
data movement from genomic sequencers to processing clusters (Sandmeyer / GHTF, Barbour, Mortazavi, Hertel, Macciardi)
-
data movement from imaging centers to (Potkin, Van Erp) to processing clusters.
-
going forward, data to and from cloud services such as Amazon EC2 and Google Compute. The main prohibition of using these services is not their computational cost, but the cost and time of data IO to these services.
4. Diagram of UCIResearchNet
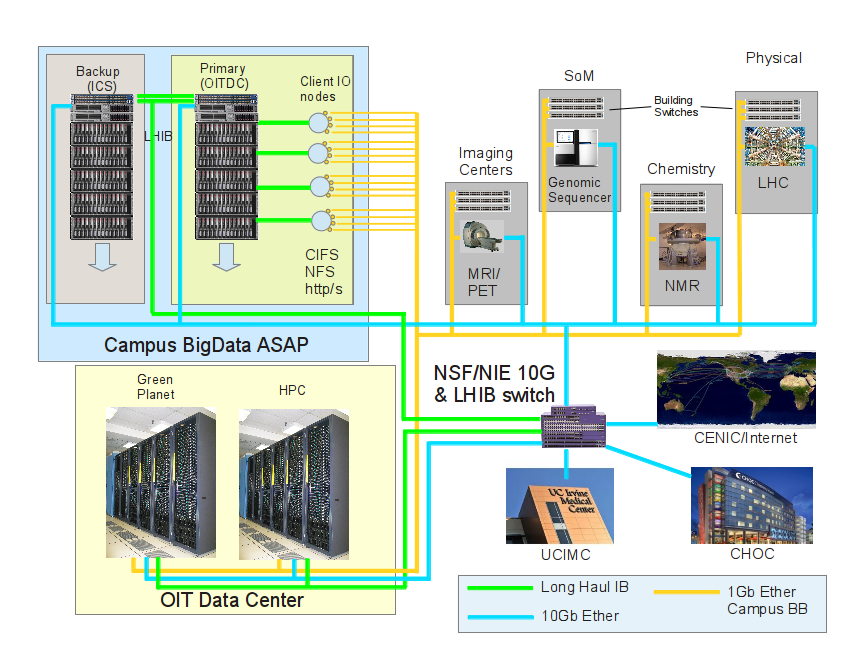
Figure 1 shows a block layout of the storage and connectivity that the UCI Research/ASAP Network would provide. As noted in the legend at the bottom of the diagram, the existing 1Gb campus ethernet backbone is shown in yellow lines. The new Long Haul Infiniband (LHIB) network is green, and the 10Gb backbone tree in blue. The actual network topologies are not shown; the 10G network is a star rather than the bus shown, for example. It’s the connections and their speeds that are important here.
The very low latency LHIB network would provide the rsync’ed replication service between the Primary storage in the OIT Data Center and the Backup storage in the ICS Data Center as well as the transport from that storage to the HPC and Green Planet compute clusters in the Data Center. Faculty clients in remote buildings (using MacOSX, Windows, Linux) would connect to the ASAP storage via the normal protocols (CIFS/SMB, NFS) via specialized IO nodes that have multiple 1GbE connections, but could also connect via Linux native clients directly. The IO nodes could also be Web servers to serve out this data to collaborators via the WWW.
The storage icons overlaid by the blue shading represent multi-chassis distributed filesystems at each point, with the Primary storage rsync’ed to the Backup one or more times a day. In the event of the Primary failing, the Backup can be reconfigured as Primary.
The 10Gb transport would also extend a large-bandwidth pipe to the campus border router to the Internet via CENIC and to the remote Medical facilities in Orange, where substantial Imaging and Genomic data is generated.
5. Cost, Constraints, & Catastrophes
A campus research storage system such as proposed above is different than an administrative or financial storage system. We have planned for cheap, fast, multi-protocol, fairly reliable, and replicated storage but it is not High Availability nor is it formally backed up. It will require scheduled downtimes of up to a day and may lose some data. The data loss scenario is described below and could be best described as unlikely, but not impossible. Over the course of its lifetime (easily a decade, since it is meant to be upgradable on the fly), it will almost certainly lose some data.
5.1. Storage Infrastructure
The actual storage infrastructure will be built out of chassis from what is known as a tier 2 vendor. We have been using Advanced HPC, based in San Diego, but for a project of this size, we would request quotes from others, including 1st tier vendors like Dell and IBM. We have found that the reliability of Tier 2 hardware is at least as good as that from a first tier vendor such as HP or Dell and is actually easier to configure since Tier 2 vendors provide essentially the same hardware devices but without proprietary software layered on top. This also avoids vendor lock-in. Buying this hardware with extended service contracts and Enterprise disks (for a total of 5 yr of coverage), provides some security in lifetime with the ability to replace generic hardware with other generic hardware, depending on industry trends and technology changes.
The Distributed Filesystem we choose will depend on a number of constraints, but will probably be either the Fraunhofer filesystem (Fhgfs) or IBM’s General Parallel File System (GPFS). Both have a lot of similarities and share some weaknesses as well. We will discuss these in other documents. The main similarity is that both are highly scalable and can be expanded on the fly. Both are commercially supported, altho IBM has a much larger customer base; it is also 5x more expensive ($1500/server for Fhgfs; ~$8000/server for GPFS).
5.2. Personel required.
The storage infrastructure will require 1 FTE for setup and initial running and will almost certainly require another FTE at some point afterwards to deal with client problems, data sharing, IO node configuration, custom scripts and data movement. This support could be done from within the EUS or RCS groups.
5.3. Scaling
Distributed filesystems are scalable on the fly. This is one very large advantage since storage has historically halved in price every 14 mo. With a distributed filesystem, we can buy storage in ~100TB chunks as we need it, instead of overbuying storage and then typically wasting half of it over it’s lifetime. See Diagrams 2a,2b below.
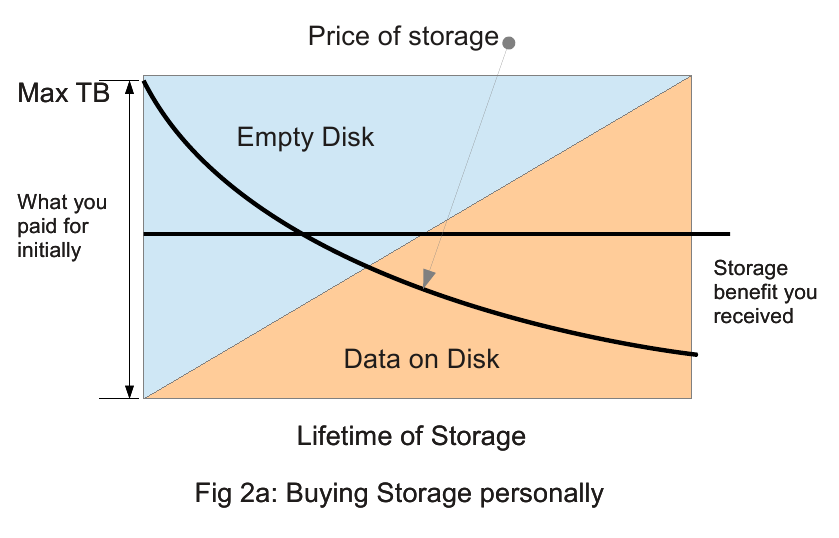
Figure 2a shows the dynamic of a small group buying a storage device for themselves. Because of the minimum useful size of a RAID, the cost of the chassis, the difficulty of adding more disks to a RAID, etc, they will usually buy a fairly large device which will gradually fill up over the course of their work, typically about 3yrs. However they have paid for this device in full upfront, so they cannot take advantage of the decreasing price of storage, except as a lower cost of failed disks perhaps. Because of this upfront purchase, the effective storage benefit of the device is only about 1/2, even ignoring the decreasing price of storage, since on average they will only have used half of it over its lifetime.
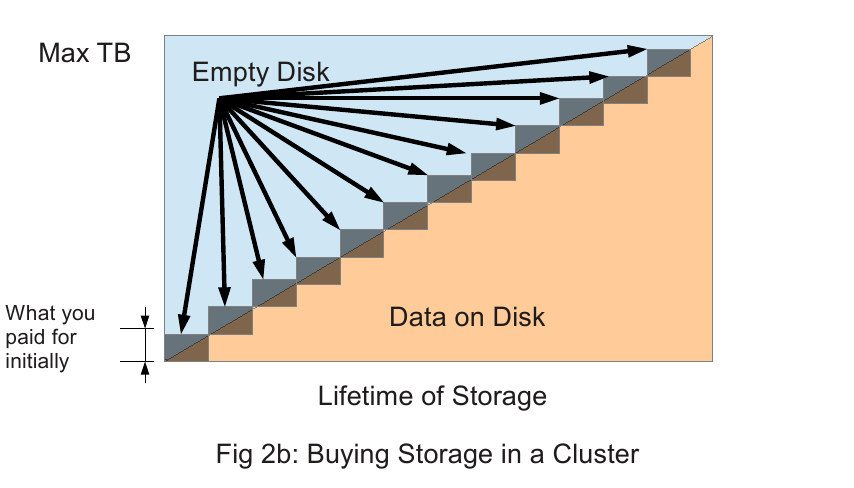
Figure 2b shows the pricing and usage dynamic of a storage cluster such as we propose. The initial buy-in is still large, but since it will be used by many more people, use will be higher and the probable increase in demand will also be large. The biggest difference is that when more storage is needed, a proportionally smaller increment is needed so that there is less wasted storage per total storage. The incremental storage is shown as the small, shaded blocks rising on the diagonal and only the upper triangle in each block is wasted. All the storage cluster has to do is to keep slightly ahead of demand so there is always space to grow into. As the system grows, new Storage and MetaData servers can be added to increase speed of access and amount of storage. All distributed filesystems also increase aggregate bandwidth as number of servers increase.
While a recharge plan is not part of this document, OIT can come up with a variety of ways to recover some of the $ that go into supporting and expanding it, such as charging extra for specifically mirrored data, charging by the TB-month, charging for specific performance access, etc.
5.4. Failure Scenarios
The following are some scenarios for how this proposed storage can fail and what the results of that failure might be.
-
Partial hardware failure, not taking down a storage node. Disks, power supplies, and sometimes fans can be replaced while the server is still up and running. All the underlying RAIDs will have a parity of at least 2, meaning that they can lose 2 disks without data loss. All storage nodes will have at least 1 hot spare to instantly replace a failed disk and we will retain several verified shelf spares in reserve. This kind of failure (routine in a large system) would not noticably affect the day to day operations of the system.
-
CPU, motherboard failure, communications failures, leading to the loss of one or more storage servers in one storage cluster. This will cause a storage failure for most files until we fix the server. The exception is replicated directories which will continue to be available. As noted below, replicated directories can be available for an extra charge as a way to reclaim some of the cost of the system. Alternatively, we could also flip the system’s access so that the backup system becomes the primary system until the primary is recovered. This would not be an HA failover, but a manual flip which would take some downtime. Also, there would be some data loss since the backup is not being written synchronously.
-
Loss of a metadata server leading to loss of access to 1/N directories. The metadata server data is rsynced to another data store so that in case of a MD server failure, it can be restored to a new one. This is not a HA failover, but unscheduled downtime until another MD server can be brought online. For a campus system, we would already have a backup MD server in place.
-
Loss of the primary Data Center. The ICS cluster can be brought forward to replace the failed primary storage cluster. This would involve downtime and small data loss (all files being modified at the time of failure would lose data.)
-
Loss of both Data Centers. At this point, we have more to worry about than where our data went. Personal storage would still be on your personal devices, but large data stores would be lost unless they were backed up elsewhere.
6. Starting Hardware Budget
(to be completed)