1. Introduction
The CLC software that UCI has licensed includes the Java-based Genomics Workbench which can be installed on your personal Mac, Windows, or Linux PC and provides a Graphical User Interface (GUI) to a number of frequently used analyses. In this respect, it is similar to DNASTAR’s Lasergene software which is available from BioSci (if interested, please contact Matthew Martinez).
1.1. Setting the License Server
In order to run this software on your personal Mac/PC, you will have to download the software directly from CLCBio, install it appropriately for your platform, and then point it at the Biochemistry license server which will allow you to check out a token to run it. The workbench will ask you to identify it when it starts up, but if you miss it on the 1st startup or need to change it, you can edit the License Server configuration by clicking:
Menu item HELP → License Manager → Configure Network License → click Manually specify license server and provide the information shown below:
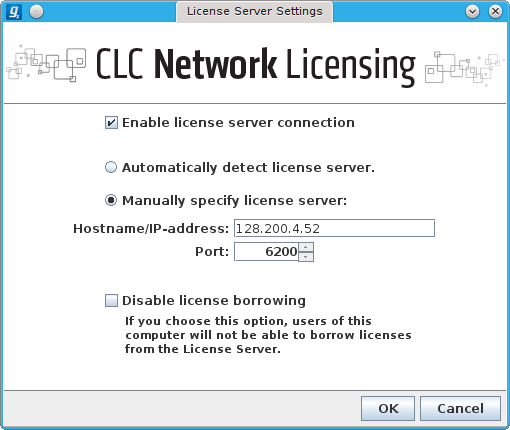
If the image above is missing, the required info is shown below in text form
[x] Enable license server connection
( ) Automatically detect license server
(o) Manually specify license server
Hostname/IP-address [128.200.4.52]
Port [6200]
[ ] Disable license borrowing
If you choose this option, users of this
computer will not be able to borrow licenses
from the License Server.
Another way in which the CLC package differs from the available Lasergene is that UCI has also licensed the CLC Genomics Server Assembler, which provides an integrated multicore assembler functionality, supporting the Illumina format among others. The machine hosting it on the HPC cluster has 64 64bit Opteron cores and 512GB RAM, so it should have sufficient resources to handle most assemblies.
There are 2 ways to use the CLC software.
-
You can use it in standalone mode, on your own machine, which supports all of the functionality. If you decide to run it on your own personal computer, just download and install the Genomics Workbench, then when starting it, direct it at the Biochemistry license server: 128.200.4.52, port 6200, as described above
-
You can use it on the HPC cluster node which means that the GUI will run a bit slower, but you will have access to the hardware resources of that 64core machine which are larger than most personal machines.
The following describes how to run it on the HPC machine.
2. Pre-Requisites
To use the CLCbio Genomics Workbench from the HPC server, you must first have an account on the HPC cluster. Mail Harry Mangalam to request one if needed.
Also, your Mac or PC must be set up to use ssh and support X11 graphics.
The CLCBio GUI is a Java application that uses the above-mentioned X11 graphics to provide the application from the HPC cluster. To log into HPC, you must use ssh, configured to tunnel X11 graphics (on Linux and MacOSX, ssh -Y); on Windows, it must be explicitly configured as described below)
2.1. Windows
If you use Windows, you’ll need to set up the x2go software as described here.
2.2. Macintosh
If you use a Mac, you’ll need to install the XQuartz software (no longer bundled with the OS). All you have to do is install it and start it running in the background to accept the X11 windows (Applications → Utilities → XQuartz).
You can then either use it standalone, or use the Mac version of x2go, which is faster (but requires the XQuartz software to work).
2.3. Linux
If you use Linux, you should be good to go already. These tools and packages are already installed on all popular distributions of Linux.
3. Logging in to the CLC server
You will have to first log into the HPC login node node and from there, qrsh into compute-3-5.
-
First connect to hpc.oit.uci.edu, then connect to the compute-3-5 node via
qrsh -q ghtf@compute-3-5
This will register an ssh -Y session with the scheduler and connect you to node compute-3-5 where the CLCBio app is licensed.
3.1. Using the x2go client
The x2go free software enabled you to start and maintain a Terminal connection to compute-3-5, even when you disconnect (for example, to close your laptop to go home or even abroad). It’s somewhat complicated to set up but it gives usable performance even across continents (most of the time).
When you start this connection, you’ll have a terminal application (the /usr/bin/gnome-terminal described in the x2go setup) so continue as described below.
3.2. Starting the CLC Workbench
Once you have qrsh’ed into compute-3-5, the process is identical for all clients.
The system will spew some informational lines and the identify itself as compute-3-5.
# then you type clcgenomicswb8
If you’ve done everthing right, the CLCBio splash screen will pop up and shortly thereafter you’ll see the whole application window. It has already been directed to the Biochemistry license server.
4. Genome data
Some genome reference data is stored in /data/apps/commondata/, which currently has human, rat, mouse, yeast, and elegans genome sequences available in compressed fasta files on a per-chromosome basis.