1. Summary
This document tells you how to add crontab entries to have your RAID controllers report X times a day how they’re feeling. If they’re feeling well, your email will look like this.
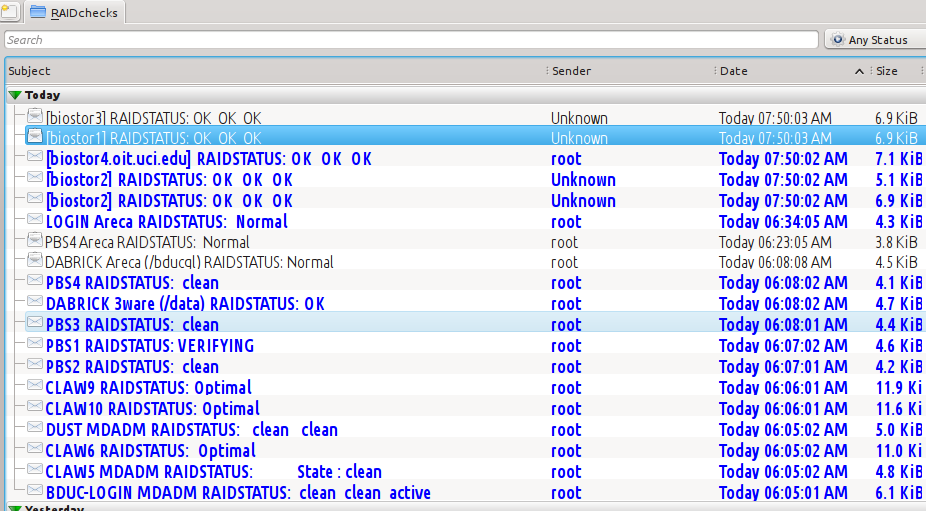 .
.
The Subject lines that contain "OK OK OK" indicate servers that have multiple RAIDs; 'VERIFYING" indicates the instantaneous state of the RAID. The different commandline utilities have different vocabularies to indicate cleanliness or state. If you need absolute identity in the vocabulary, you can spiff up the test script with some regex matching to provide it.
2. Introduction
This is a common problem - you’ve got a zillion Linux servers, each with its own RAID controller and your skin is on the line if any of them loses data.
Each of the %$% controllers has a different Web interface, with different scheduling options and each of the %$#% things has a different commandline tool for probing the controller/raid guts - some of them are truly, phenomenally, execrably, vomitaciously awful.
The usual failure case is that:
-
you haven’t configured the email to work because all of the %$#%^ proprietary systems have their own mailing systems / setup and its a PITA to set them up and verify them (or you set them up and one of them silently loses the email service).
-
and then the disks fail silently and the RAID degrades disk by disk until one morning you get the dreaded WTFIMD? email from a client and you have to explain that …. it’s complicated…
In an unusual attempt to be more efficient, I’ve put together a bunch of crontab scripts that will issue a report X times a day for these controllers:
-
LSI, using the execreble MegaRaid MegaCli (I have recently heard from LSI that this was never meant to be seen by humans (only engineers) but was released contractual reasons. Since they bought 3ware, they will soon use 3ware’s much better tw_cli (see below).
-
3ware, now part of LSI, but existing 3ware controllers still have their own, (better) commandline utility - tw_cli
-
Adaptec, using the StorMan arcconf utility
-
Areca, using the cli64
-
the special case of mdadm, which can run software RAID over most of the above controllers.
So here are my crontab entries for all of the RAID systems mentioned. If you’re at all interested in this, you’ll probably know what to modify
3. The crontab entries
For the following entries, some things obviously have to be changed: the controller value in many cases, the subject line if you want to include more example, and of course the email recipient Many of the vendors supply different versions of their software with different hardware; the version of the software that I reference is the one that I used.
Also, for email to work, you’ll have to have a mail agent such as exim4 or postfix running each of the servers, generally pointing to an institutional SMTP server as well as mutt.
3.1. LSI
You’ll need the MegaRaid utility - choose one or search from this page.
3.1.1. crontab entry
# m h dom mon dow command 7 6,20 * * * HOST=`hostname`;SUB=`/opt/MegaRAID/MegaCli/MegaCli64 \ -CfgDsply -a0 |grep '^State'|tr -d ' '|cut -f2 -d:`; \ /opt/MegaRAID/MegaCli/MegaCli64 -CfgDsply -a0 \ | mutt -s "$HOST RAIDSTATUS: $SUB" <email_recipient>
3.1.2. Output
The output for the LSI email is long; view it here.
3.2. 3ware
You’ll need the tw_cli utility, usually bundled with the rest of the 3ware 3DM2 web interface.
3.2.1. crontab entry
# m h dom mon dow command 07 6,20 * * * HOST=`hostname`;SUB=`/usr/bin/tw_cli '/c2 show' \ | grep RAID| cut -c17-25`; /usr/bin/tw_cli '/c2 show'| mutt -s "$HOST \ RAIDSTATUS: $SUB" <email_recipient>
3.2.2. Output
Unit UnitType Status %RCmpl %V/I/M Stripe Size(GB) Cache AVrfy ------------------------------------------------------------------------------ u0 RAID-5 OK - - 256K 3259.56 ON ON Port Status Unit Size Blocks Serial --------------------------------------------------------------- p0 OK u0 465.76 GB 976773168 3PM0A1BY p1 OK u0 465.76 GB 976773168 3PM0GH46 p2 OK u0 465.76 GB 976773168 9QG06MT6 p3 OK u0 465.76 GB 976773168 9QG06RDL p4 OK u0 465.76 GB 976773168 3PM0G6W6 p5 OK u0 465.76 GB 976773168 3PM0G747 p6 OK u0 465.76 GB 976773168 3PM0BVG2 p7 OK u0 465.76 GB 976773168 3PM0CD2N Name OnlineState BBUReady Status Volt Temp Hours LastCapTest --------------------------------------------------------------------------- bbu On Yes OK OK OK 0 xx-xxx-xxxx
Altho the tw_cli software can detect it, the 3Dm2 monitoring software does not warn on reallocated sectors so these may go unreported until the disk fails. Increasing reallocated sectors are an indication that the disk is failing, so it’s good to have some warning of this. This sectorchek.pl script will detect and report reallocated sectors as well as any disk that is in any non-OK state - I had one instance where a disk went into an ECC ERROR state but the 3DM2 report didn’t mention it.
3.3. Adaptec Integrated controllers
You’ll need the Adaptec arcconf utility - choose the correct version from this page.
3.3.1. crontab entry
# m h dom mon dow command 7 6,20 * * * HOST=`hostname`;SUB=`/usr/StorMan/arcconf GETCONFIG 1 \ |grep ' Status ' | cut -f2 -d: |tr -d '\n'`; /usr/StorMan/arcconf GETCONFIG 1 \ | mutt -s "$HOST RAIDSTATUS: $SUB" <email_recipient>
3.3.2. Output
The output of the Adaptec email is also fairly long; view it here.
3.4. Areca
You’ll need the Areca commandline interface
3.4.1. crontab entry
# m h dom mon dow command 7 6,20 * * * HOST=`hostname`;SUB=`/root/areca/cli64 rsf info raid=1 \ |grep "Raid Set State" | cut -f2 -d:`; /root/areca/cli64 rsf info raid=1 | \ mutt -s "$HOST Areca RAIDSTATUS: $SUB" <email_recipient>
3.4.2. Output
Raid Set Information =========================================== Raid Set Name : BDUC home Member Disks : 15 Total Raw Capacity : 15000.0GB Free Raw Capacity : 0.0GB Min Member Disk Size : 1000.0GB Raid Set State : Normal =========================================== GuiErrMsg<0x00>: Success.
3.5. mdadm
mdadm deserves a special mention - it’s very simple to set up and administer; it was designed for sysadmins and commandline use. It has a simple, fairly understandable configuration file and very good man page. Finally, the author, Neil Brown is almost always available on the Linux RAID listserv and is willing to answer reasonable questions (and if he isn’t, many other mdadm users are. mdadm is a gem. You’ll need to change the md device (/dev/md0 below) and you’ll obviously need the mdadm software; it’s called mdadm in both Debian and RedHat repo’s.
3.5.1. crontab entry
# m h dom mon dow command 07 6,20 * * * HOST=`hostname`;SUB=`/sbin/mdadm -Q --detail /dev/md0 \ |grep 'State :' |cut -f2 -d:`; /sbin/mdadm -Q --detail /dev/md0 | \ mutt -s "$HOST RAIDSTATUS: $SUB" <email_recipient>
3.5.2. Output
/dev/md0:
Version : 00.90
Creation Time : Wed Nov 19 15:04:51 2008
Raid Level : raid1
Array Size : 192640 (188.16 MiB 197.26 MB)
Used Dev Size : 192640 (188.16 MiB 197.26 MB)
Raid Devices : 2
Total Devices : 2
Preferred Minor : 0
Persistence : Superblock is persistent
Update Time : Wed Oct 3 20:08:02 2012
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
UUID : 164af41a:07a8c1c4:70b12226:52f0beed
Events : 0.446
Number Major Minor RaidDevice State
0 8 33 0 active sync /dev/sdc1
1 8 17 1 active sync /dev/sdb1
In my setups, the crontabs all fire at the same time so that all of the hosts come in (or don’t) simultaneously - it’s usually obvious which ones don’t. If you need better attendance counting, you can filter them into separate email folders so that it’s more obvious if you have crontab or email failures.
These scripts not only send you an OK / not OK in the subject header but ~ a page-ish summary of the RAID/controller status.
Corrections, additions, suggestions back to me.