|
|
Some Notes
This document is a few years out of date, but much of it remains relevant. I have retitled it to adapt to the name change of FhGFS to BeeGFS (but have left the internal references to FhGFS and have updated parts of it, usually based on questions I’ve received from those wo have stumbled upon it in the dustier corners of the Intertubes. To answer the most often asked question: Yes, we’re still using it and we very much like it. In the HPC world, it is a rare piece of software that is Open Source, commercially supported, well-documented, and overwhelmingly works as described. It’s a very fast Camry compared to Gluster’s 1973 Chevy van or Lustre’s Ferrari (which can be faster, but requires a fulltime mechanic to ride along with you and often unexpectedly loses a wheel). More in-line if you care to read that far. If you have specific questions about our BeeGFS use cases, I’d be happy to anwer them. Besides a T-shirt, I have no financial ties to ThinkParq, BeeGFS, or the Fraunhofer Institure, except as a very satifisfied customer. |
1. Summary
We evaluated the Fraunhofer (FhGFS) and Gluster (Glfs) distributed filesystem technologies on multiple hardware platforms under widely varying conditions. While the variations in most of our test conditions made it difficult to make direct comparisons, we can make some useful comments.
NB: This commentary was recently (June26th, 2014) to include more comments about performance under real-life load which make the case much stronger for FhGFS.
-
Both Glfs and FhGFS are free, but Glfs is also Open Source Software (OSS), which can be useful in tracking down bugs. FhGFS has Open Sourced the client and is considering making the server OSS as well, but that has not happened yet.
-
Both Glfs and FhGFS are very forgiving in terms of hardware. They can be run on just about anything. Neither requires special kernel modules nor patches (unlike Lustre). Neither is distro-locked and both can be installed easily on both Debian and RH-derived distros.
-
Gluster uses an on-disk but cached structure to organize metadata (in extended attributes) (the Distributed Hash Table or DHT). FhGFS uses logically separate and physically separable metadata servers to do the same. Both approaches have pros and cons.
-
Glfs has much more active support systems (forum and IRC) and is commercially supported by RedHat. You can get commercial support for FhGFS from Fraunhofer.
-
Glfs can be used in both distributed and distributed-replicated (as well as geo-replicated) form. See this PDF reference describing the different formats that Gluster can support.) FhGFS can also be completely or partially replicated, altho I did not test this functionality with either Gluster or FhGFS. Glfs has many more functions built-in to support typical large filesystem operations, such as clearing a brick, migrating a brick, balancing bricks, etc. FhGFS has a subset of these functions. Neither are magic and migrating several hundred TB is a multi-week operation on an active FS.
-
Both scale input/output (IO) operations as advertised, eliminating the single bottleneck of NFS servers.
-
Both have very good streaming IO on large files, although Glfs is about 2x as fast on large streaming writes as FhGFS using the same hardware, however the performance on Glfs degrades much more rapidly than on FhGFS under heavy IO.
-
Both have good logging facilities which is a necessity in debugging problems.
-
Both operate well over Infiniband and Ethernet simultaneously, however only FhGFS currently supports RDMA. Gluster has RDMA support in the code, has supported it, and indicates that they will soon support it again. Both support IPoIB.
-
Glfs has a severe problem with small writes, both with writing small files and small writes into large files. FhGFS does not have this bottleneck.
-
We see rare but repeated write failures using Glfs. We think we have tracked this down to instances where array jobs are writing thousands of files and are then immediately reading from them or using the existance of those files as job control. We see this only during huge job arrays of a particular type and even then, quite infrequently. However, write failures on a FS are not acceptable.
-
Glfs is very slow on recursive operations (ls, du, find, grep, etc), making it almost unusable for interactive operations on large filesytems. There are some workarounds. FhGFS is 5-60x faster than Glfs for these operations, often faster than a native filesystem or NFS. The RobinHood Policy Engine is a very useful tool for both these filesystems.
-
FhGFS has a good GUI for first time installation and monitoring, but GUI modification of that installation is difficult and manual modification of it is also tricky unless you know what you’re doing. Use the manual installation and stay with it. Glfs has had (and probably will have) a GUI at some point but does not currently have a freely available GUI administration tool.
-
Unless explicitly configured differently at initiation, Glfs stores each file on one brick under the native file name. This has pros and cons, but we often run into situations where this was a problem with one large source file is being queried continuously over several days, bottlenecking the IO of that brick. Because FhGFS distributes its files across all bricks, this would not have happened. Recent versions of Glfs CAN be configured to stripe files across bricks, altho it’s based on predefining a minimum size that will stripe.
-
Both filesystems benefit from good underlying hardware. We tested both on the LSI Nytro SSD-backed SAS controllers and the improvement in performance was dramatic vs an older 3ware 9750 SAS controller.
|
|
BEWARE the LSI Nytro controllers
Recently, we have had 3 catastrophic failures with these controllers and therefore cannot recommend them (academic, since they aren’t made anymore). If you have one of these controllers, you might look into replacing them with a non-Nytro equivalent. In the process of attempting recover from these failures, we noted several bugs in LSI’s recovery process and software and would recommend extreme caution in using their hardware controllers at all. They are great when they work, but they leave a gut-wrenching mess when they don’t. (Oh look Johnny! a PB of user data has ceased to exist!) We are moving to ZFS-based storage with very simple pass-thru controllers that can be replaced with other vendor products (ie LSI <→ Supermicro). |
2. Introduction
We are currently using Gluster for our compute cluster’s distributed filesystem in its distributed-only form and while it scales well, has reasonably good documentation, utility support, and an active online support community, we have had issues due to the above-mentioned problems that have not been resolved, forcing us to consider alternatives.
2.1. What is a distributed filesystem?
Distributed filesystems are those where the files are distributed in whole or in part on different block devices, with direct interaction with client computers to allow IO scaling proportional to the number of servers. Acording to this definition, a network-shared NFS server would not be a distributed filesystem, whereas Lustre, Gluster, Ceph, PVFS2 (aka Orange), and Fraunhofer are distributed filesystems, altho they differ considerably on implementation details. While NFS is a well-debugged protocol and has been designed to cache files aggressively for both reads and writes, the single point bottleneck for IO, is a real weakness in a compute cluster environment.
2.2. Why not Lustre, Ceph, PVFS2/Orange, etc
We did not test Lustre, due to the widely held perception (and 2 bad past experiences) that it is very fragile to software stack & driver changes. Our users have said loudly that they value stability over speed. However, once Lustre produces a stable 2.4 series that supports Lustre-on-ZFS that doesn’t require an entire FTE to maintain it, we’ll try it. We tried Ceph about a year ago and it wasn’t nearly ready for production use. OrangeFS was interesting but there were so few mentions of it on the Internet and the overall traffic was so low that we decided to skip it. IBM’s GPFS is a very mature and capable filesystem that interfaces with other IBM products such as Tivoli and is supported by the full faith and credit of IBM, but as you might guess, it’s also quite expensive for a cluster filesystem (about $8K per server). We were looking for a free alternative. Via some web-browsing and direct recommendations, we decided to try Fraunhofer as an alternative, so this document will only discuss the Fraunhofer and Gluster filesystems.
2.3. What will decide a move from Gluster to Fraunhofer?
Since we’re in production with Gluster, we have a vested interest in keeping it. It does work pretty well, with the few disadvantages mentioned above. Since that is the case, we will base our decision on these points:
-
How much faster is FhGFS, if at all?
-
How hard is it to replace or transition our existing 340TB Gluster system.
-
Can the gluster performance be addressed by hardware upgrades? And how easy is it to transition between hardware upgrades?
-
What features (beyond performance) does the replacement offer? and how well do they work? ie, do the implied features actually work?
-
What kind of response do we get from support fora and IRCs?
-
How widespread is the technology and how many people are similarly invested in using it?
See the Conclusions for the answers to these questions.
2.4. Can Hardware Upgrades solve the problem?
Can an SSD caching controller provide enough of a speed increase to address the current problems?
The disk controller on the Glfs2 test system uses on-board SSDs as part of the caching system, so rather than using expensive DRAM to provide a couple of GB that previous controllers might, the LSI Nytro 8100 4i embeds 90GB of SSD (specs say 100GB, but only 90 is usable) on the controller board and splits it to allow 45GB for write and read caching. It’s not clear that it’s dynamically balanced (ie uses more cache for reads if the job is read-heavy and vice versa). This architecture seems to be heavily influenced by the success that FusionIO has had with their very high performance (and very expensive) caching accelerators and now we’re starting to see these SSD-based accelerators integrated into prosumer grade controllers. While these are more expensive than their non-SSD products, it’s a small part of a large filesystem and their performance is quite impressive on single nodes; we are testing them to see what kind of performance benefit they give to distributed filesystems.
See the Conclusions for the answer to this questions.
3. The testbed hardware
3.1. Fraunhofer Filesystem
We ran 3 versions of FhGFS - one on old hardware (FhGFS1) and another (FhGFS2) on new hardware, using the LSI Nytro controller mentioned above, and a 3rd (FhGFS3) which used split metadata servers from FhGFS1 with the newer hardware from FhGFS2. The dual metadata servers were connected via DDR IB to the same QDR switch as the storage servers and the clients. RDMA was used across all machines. MTU was set to 65536.
FhGFS1: This system ran on 4 storage servers, each of which has 4x64b Opteron cores, 16GB RAM (1 has 8GB) and 4-8 7K SATA disks in RAID5 config. The bricks used default XFS format. The metadata was split over 2x4core/16GB machines with single 120GB SATA ext4-formatted disks (default settings; no additional tuning).
-
2 ran with mdadm software raid on Supermicro/Marvell MV88SX6081 controllers with a total of 8.2TB each
-
2 ran with hardware raid (3ware Inc 9550SX and Areca ARC-1130) with a total of 6.4TB each. all 4 used RDMA transport on Mellanox MT25204 DDR Infiniband cards all running thru a Voltaire QDR switch
FhGFS2: This system ran on 2 recent servers from Advanced HPC. They both used the same chassis, but differed slightly internally. One used an 8core AMD CPU while the other uses a 12core Intel CPU. The metadata server was a single 8core/64GB machine using an 87GB ext4 partition (7K SATA disk). It is NOT recommended to use such small metadata server storage for such a large filesystem. At the end of our testing, with only a small fraction of the main filesystem used, we ran into inode starvation on the metadata server and had to do some re-jiggering to allow the test to continue. This is mentioned in the FhGFS documentation, but I managed to miss it.
-
1 x 8core Opteron, 128GB RAM
-
LSI Logic / Symbios Logic MegaRAID SAS 2208 [Thunderbolt] controller (aka Nytro 8100 4i, with 2x45GB SSD caches). This is a new architecture for controllers that places 1 x 12-core Intel® Xeon® CPU E5-1650, 128GB RAM with the same controller
Both had 2x RAID6 arrays on the same controller, one with 18 disks; one with 17 disks. They used the same disks, the Hitachi 3TB SAS disks Model HUS723030ALS640.
This was strictly a test system, otherwise idle.
FhGFS3: This system used the same 2 storage servers that FhGFS2 used, but used the same 2 metadata servers (one also ran the Management Daemon) as FhGFS1, with slightly different storage. The metadata was placed on a RAID1 system that was tuned specifically to the FhGFS metadata recommendations. The storage server RAID systems were also tuned to the FhGFS storage recommendations for XFS formatting and mount options, IO scheduler, and Virtual Memory settings. See Configuration below.
3.2. Gluster Filesystem
Glfs1: This system is running on 4 identical 36-slot SuperMicro chassis' from Advanced HPC similar to the ones described above, differing mostly in the disk controller and RAM. Each of the 4 systems consisted of:
-
8core AMD Opteron 6212, 1.4GHz, 32GB RAM
-
3ware Inc 9750 SAS2/SATA-II RAID PCIe (rev 05) controller, also with 2 RAID6s of 3TB 7K SATA Seagate ST3000DM001 Desktop disks - one of 18 spindles, one of 17 spindles. It uses Mellanox MT26428 QDR IB IPoIB transport thru the same Voltaire QDR switch as the other configurations
The 3ware Glfs1 above is in production; glusterfsd’s are running at a steady load of 1.5 - 2 continuously, supporting an academic compute cluster of ~2500 cores with an average aggregate load of about 43% over the last month.
Glfs2: This system was identical to the one noted above for FhGFS2.
3.3. Direct Attached Storage / RAID5 (DASR5)
A few tests were run on a Direct-Attached 6-spindle RAID5 (3TB, 7K SAS disks), hosted on a 64core, 512GB compute node. This fs is a testbed which was essentially idle.
4. The tests
I used 10 tests altogether to evaluate the filesystem performance. None were standard filesystem benchmarking tests since these often do not reflect real load and certainly do not reflect distributed cluster loads.
-
5 write tests, one using dd, the other using 2 tarball extractions, and 2 others that wrote a large file, once using multiple small writes and the other using a single large write.
-
2 pure read tests using recursive grep thru large file trees
-
2 recursive tests using ls and du
-
a mixed read/write test which involves compiling the linux kernel 3.7.9
Most of these tests were done as cluster jobs in which the test was clusterforked to 9 cluster nodes such that each node did the test simultaneously. This kind of test reflects the cluster environment more accurately than a single node executing the test. The 9 cluster nodes were connected using QDR IB. Each has 64 cores and 512GB RAM, so they were not usually RAM or processor-limited (altho they were often under variable load which was usually measured prior to the test.
4.1. Write (dd)
The write test was a simple script that started 10 simultaneous dd sessions on each node, each one pushing 2GB from /dev/zero to files on the target filesystem for a total of 9nodes*2GB*10instances/node=180GB of data.
I acknowledge there are a number of problems with using dd and /dev/zero: the underlying filesystem may not match the blocking of dd, the controller may do inline compression (which would make short writes of zeros highly compressible), etc, but it’s often used and since we’re measuring the time to sync to disk, it’s a convenient shorthand for streaming writes.
The results indicate that for such writes, while the old hardware used for FhGFS1 restrained its ability to push data thru to the disks, FhGFS2 (on new hardware) was about as fast as the Glfs1 test system, but could not match the Glfs2 write speed (which used identical hardware). Gluster was almost 2X as fast with streaming writes. Note that on 2 ocassions, I tried to write this same amount to the local filesystem (DASR5) and both times it locked up.
|
|
Win for Gluster. |
| Filesystem | Avg Time(s) ± SEM | Loadavg ± SEM | starting IO ± SEM |
|---|---|---|---|
FhGFS1 |
1005 ± 0.647 |
||
971 ± 2.2 |
14.9 ± 3.5 |
3580 ± 1527 |
|
FhGFS2 |
94 ± 5.7 |
21.6 ± 6.7 |
0.072 ± 0.02 |
128 ± 0.1 |
21.4 ± 6.7 |
0.078 ± 0.04 |
|
124 ± 0.06 |
21.4 ± 6.7 |
4274 ± 1812 |
|
FhGFS3 |
81 ± 0.71 |
46.9 ± 5.37 |
8971 ± 3217 |
89 ± 0.5 |
49.3 ± 5.58 |
334 ± 117 |
|
88.6 ± 0.3 |
17.4 ± 5.3 |
0.03 ± 0.001 |
|
84.08 ± 0.268 |
18.7 ± 5.7 |
18.51 ± 6.6 |
|
Glfs1 |
130 ± 56 |
||
160 ± 24 |
10.7 ± 3.3 |
3548 ± 1514 |
|
115 ± 7.8 |
17.6 ± 5.2 |
0.01 ± 0.004 |
|
157 ± 7.7 |
17.7 ± 5.2 |
0.04 ± 0.01 |
|
Glfs2 |
58.9 ± 3.8 |
||
79.6 ± 4.7 |
14.9 ± 3.5 |
3541 ± 1510 |
-
Loadavg is the reading from /proc/loadavg just before the test
-
starting IO is the 10s average from the Infiniband interface just before the test.
4.2. Write (untar)
4.2.1. untar On Single nodes
When untarring the Linux kernel tree (80MB; 46K files), on a single node in a single process, FhGFS2 was as fast as the DASR5, which is quite impressive. Glfs2 was slightly slower, perhaps slowed by having to deal with Gluster’s Distributed Hash Table (DHT) and associated lookups. Again, the FhGFS1 was hampered by inferior hardware altho it still managed to be 2x as fast as Glfs1, altho this may have been due to the cluster load on Glfs1 (which was not measured at this point).
The core command for this test was:
sync && echo 1 > /proc/sys/vm/drop_caches; time (tar -xjvf /tmp/tarball.tar.bz2 && sync)
| Filesystem | 80MB/46Kf (s) | 2GB/30Kf (s) |
|---|---|---|
FhGFS1 |
435 |
948 |
FhGFS2 |
107 |
99 |
FhGFS3 |
79 |
82 |
Glfs1 |
1010 |
699 |
Glfs2 |
181 |
162 |
DASR5 |
109 |
176 |
While it was not measured on all platforms, untarring the 80MB tarball on all 9 nodes simultaneously to different paths on FhGFS2 took only 430 ± 6.8 s, only 4 times longer than on a single node.
When untarring a larger tar file but with fewer files (2GB, 30K files), the difference was even more striking - better hardware made a big difference but the the number of inodes having to be handled made an even bigger difference. Even tho significantly more Bytes were being handled, the speed at which the data could be handled increased for all but the FhGFS1 test. On recent hardware, the time it took to process even more data decreased and both FhGFS2 and Glfs2 beat even the DASR5 local storage, FhGFS2 completing in about half the DASR5 time.
|
|
Win for FhGFS2 (and the hardware). |
4.2.2. untar On Multiple nodes in parallel
When the load was increased by 9fold as might the case ina cluster environment, the improvement in hardware makes a huge difference. There was a >10x improvement in the IO for the new hardware for handling this amount of data. A significant part of this improvement is certainly due to the LSI Nytro controller as the main difference between the Glfs1 and Glfs2 systems was the controller which allowed the Glfs2 to beat the Glfs1 system by 5X-10X, even tho it had half the number of nodes and spindles as Glfs1.
| Filesystem | Time ± SEM (s) | Loadavg ± SEM | background IO ± SEM |
|---|---|---|---|
FhGFS1 |
4120 ± 17 |
33 ± 3 |
6783 ± 2682 |
FhGFS2 |
326 ± 3 |
37 ± 6 |
7309 ± 3096 |
286 ± 2.1 |
36 ± 6 |
5632 ± 2437 |
|
278 ± 2.6 |
13 ± 5 |
7131 ± 3022 |
|
284 ± 1.6 |
12 ± 2 |
6306 ± 2691 |
|
285 ± 2 |
12 ± 5 |
6503 ± 2775 |
|
FhGFS3 |
230 ± 11 |
51 ± 5.7 |
83.7 ± 26 |
237 ± 11 |
51 ± 5.8 |
454 ±167 |
|
Glfs1 |
2704 ± 30 |
33 ± 3 |
3923 ± 1541 |
1486 ± 67 |
39 ± 5 |
11235 ± 2975 |
|
2210 ± 92 |
43 ± 6 |
4827 ± 2045 |
|
Glfs2 |
270 ± 9 |
36 ± 2 |
3887 ± 1558 |
Note: As implied by the multiple values, this test was repeated several times over the course of a day to get a feeling of how much the time would vary under differing cluster loads.
|
|
Tie for FhGFS2 and Glfs2 (and win for the hardware) |
4.3. Write (Small writes)
This test writes 20GB of data in one of 2 ways: either as multiple individual Perl print statements of 100 chars each to STDOUT or as the same amount of data stacked in memory and written with a single print statement. This demonstrates the different ways the 2 filesystems handle single files - FhGFS distributes the files over the available bricks, while Gluster writes single files to individual bricks.
The results of this test, in which 20GB of data is written in 2 formats
| Filesystem | small writes(s) | big write(s) |
|---|---|---|
FhGFS2 |
94 |
154 |
FhGFS3 |
75 |
136 |
Glfs1 |
519 |
566 |
Glfs2 |
omitted |
omitted * |
DASR5 |
137 |
219 |
* This test was mistakenly skipped on the Glfs2 system and the servers are no longer available.
|
|
Win for FhGFS |
The write profile partially explains the difference observed between Glfs1 and FhGFS2.
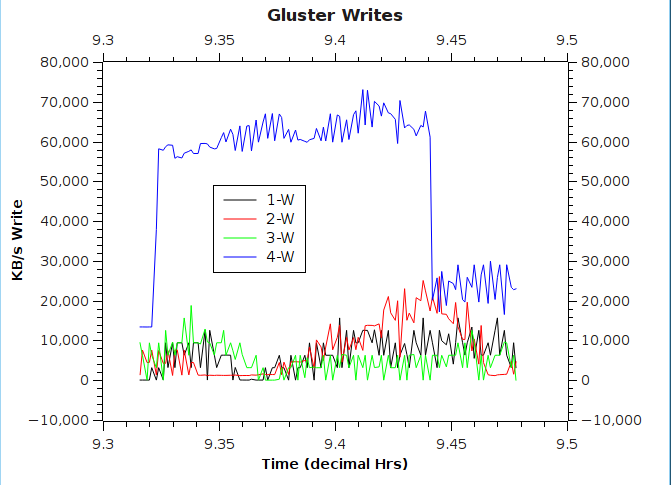
Note that only one server (4-W) gets all the data during the write.
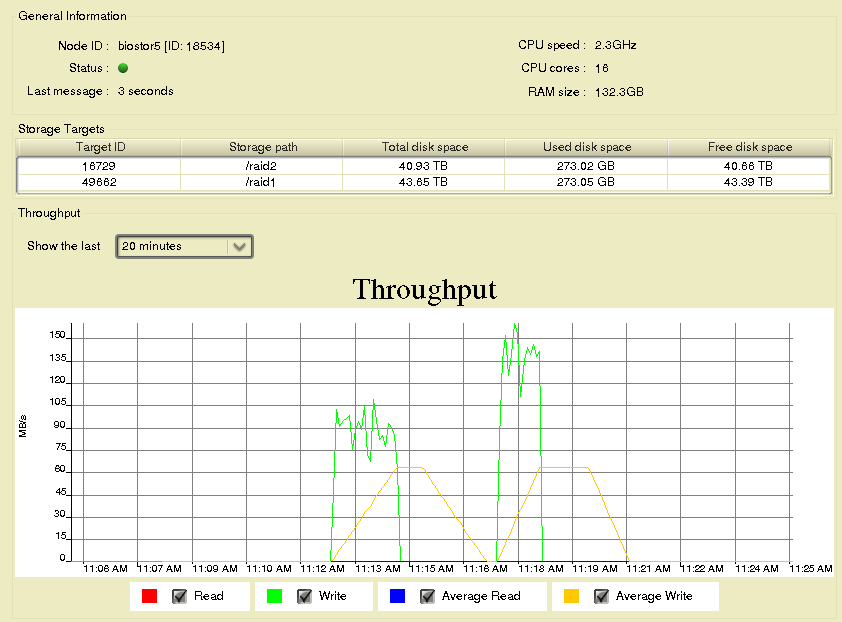
Note that one server (biostor5) gets half the total written bytes
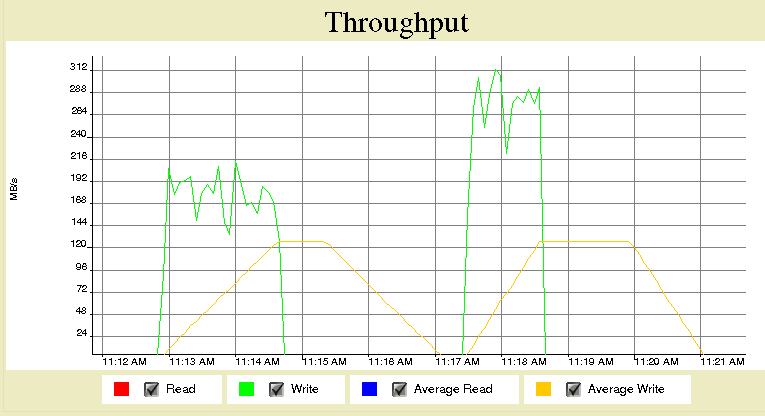
Note the total bytes being written.
While the Glfs1 filesytem was much slower than the FhGFS2 in this case, it was surprising that the big write took longer than the small writes. This has not been the case for other instances and both myself and another researcher at UCI found the same thing previously: that accumulating data into larger chunks and then writing it yielded much better performance. I cannot explain why this is not the case here.
The core command for this test was:
cf --tar=c3up --timeout=3h 'time /data/hpc/bin/multi-grep.sh' # of which the core command was sync && echo 1 > /proc/sys/vm/drop_caches; time ls -lR raporter/ | grep '^d' |wc
4.4. Read (grep)
The read test was a simple recursive, case-insensitive search for peter thru the entire (compiled) linux kernel 3.7.9 tree. This tests the ability of the filesystem to stream multiple reads to competing nodes. In this case, the DASR5 was NFS-mounted to all the other nodes and the aggressive caching allowed all the client to hit the cache fairly well. All but the FhGFS1 system did fairly well, and based on the scatter of the data, no distributed system seemed to be better than the other under load.
| Filesystem | Time ± SEM (s) | Loadavg ± SEM | background IO ± SEM |
|---|---|---|---|
FhGFS1 |
793 ± 14 |
29.6 ± 5.9 |
|
776 ± 76 |
14.5 ± 3.4 |
3422 ± 1459 |
|
FhGFS2 |
558 ± 5.0 |
17.8 ± 4.4 |
2883 ± 1233 |
557 ± 3.1 |
24 ± 6.2 |
2851 ± 1216 |
|
FhGFS2 |
558 ± 5.0 |
17.8 ± 4.4 |
2883 ± 1233 |
FhGFS3 |
500 ± 29 |
60 ± 2 |
26988 ± 11574 |
515 ± 29 |
60 ± 3 |
22052 ± 9381 |
|
Glfs1 |
563 ± 5.7 |
||
Glfs2 |
419 ± 24.5 |
29.7 ± 6.3 |
|
365 ± 9.6 |
46.9 ± 1.68 |
3765 ± 1490 |
|
DASR5 |
115 ± 12.3 |
Run with clusterfork via the multi-grep.sh script
cf --tar=c3up 'time /data/hpc/bin/multi-grep.sh' # of which the critical line is as follows: sync && echo 1 > /proc/sys/vm/drop_caches; time grep -ri peter /fsmount/path/to/linux-3.7.9/* |wc
|
|
Win for Gluster. |
4.5. Read (Recursive ls)
This involved a single node recursing thru a directory tree of 1814 dirs and 28619 files. This tests the simple single user doing recusive queries of the data, something that interactive use often involves. Here the Direct Attached Storage was enormously faster than any of the distributed filesystems, but among the distributed ones, FhGFS was >2x faster, even with FhGFS1 running on extrmely inferior hardware. Here we can credit the metadata server-mediated layout as opposed to the DHT organization of Gluster. The Nytro controller seemed to help decrease the query time to 1/2 to 1/3 compared to the 3ware 9750-based filesystem.
4.6. read (Recurse directory info with ls and du)
# ls command sync && echo 1 > /proc/sys/vm/drop_caches; time (ls -lR raporter/ | grep '^d' |wc) # du command sync && echo 1 > /proc/sys/vm/drop_caches; time du -sh raporter
executed on 64core node that had load of 2.
| Filesystem | ls -lR | du -sh |
|---|---|---|
FhGFS1 |
13 |
13 |
13 |
||
FhGFS2 |
14 |
4 |
15 |
||
FhGFS3 |
8.5 |
2.7 |
Glfs1 |
90 |
62 |
69 |
||
Glfs2 |
35 |
30 |
32 |
||
DASR5 |
0.5 |
0.1 |
0.6 |
|
|
Win for FhGFS. |
4.7. Mixed IO test
The mixed IO test is one which does a make clean and then a make -j8 bzImage of the linux kernel 3.7.9 to completion. It is also executed on 9 nodes and tests the ability of the filesystem to respond to a diverse mix of small reads and writes of various sizes. Surprisingly, FhGFS1 comes out fairly well in this test, beating Glfs1 despite much inferior hardware. Also surprising is that when running on equally fast hardware, Fgfs2 and Glfs2 are surprisingly close.
Given the speed at which FhGFS1 can complete this test, I would have expected FhGFS2 to have run much faster, however perhaps what we’re seeing is the asymptotic approach to the consumption limit. ie make -j8 cannot consume data as fast as the data can be supplied. To test this, I modified the test to use make -j32 to see if that increased the speed of the test. For the FhGFS2 test, it did, significantly, reducing the time to 1/2. For the Glfs1, it did not, increasing the time to completion.
| Filesystem | Time ± SEM (s) | Loadavg ± SEM | background IO ± SEM | make -j # |
|---|---|---|---|---|
FhGFS1 |
1980 ± 39 |
32.7 ± 4.2 |
8 |
|
2031 ± 29 |
38.1 ± 2.7 |
1516 ± 434 |
8 |
|
FhGFS2 |
1816 ± 71 |
16.31 ± 5.5 |
5833 ± 2488 |
8 |
1878 ± 33 |
17.1 ± 5.0 |
7096 ± 3027 |
8 |
|
936 ± 5 |
2.46 ± 0.0 |
10362 ± 4108 |
32 |
|
1103 ± 6 |
1.9 ± 0.2 |
2622 ± 1703 |
32 |
|
FhGFS3 |
1995 ± 98.7 |
64.5 ± 1.1 |
29.2 ± 9.5 |
8 |
Glfs1 |
2636 ± 105 |
18.5 ± 5.2, |
1978 ± 822 |
8 |
2624 ± 91 |
39.1 ± 1.1, |
2291 ± 1.3 |
8 |
|
2931 ± 29 |
8.6 ± 4.6 |
6303 ± 2509 |
32 |
|
3339 ± 59 |
29 ± 10.4 |
2995 ± 1192 |
32 |
|
3225 ± 95 |
10.7 ± 7.5 |
3993 ± 1511 |
32 |
|
Glfs2 |
1557s ± 82 |
41.4 ± 0.8 |
1440 ± 567 |
8 |
1606s ± 73 |
36.5 ± 2.8 |
1397 ± 450 |
8 |
|
|
Win for FhGFS |
For a baseline, make -j8 on a single node using the DASR5 takes 126s. and make -j32 takes 65.5s
Command for this test was:
cf --tar='c3up' --timeout=3h 'time /data/hpc/bin/multi-makekernel.sh'
5. Conclusions
Following are the conclusions that we came to in this comparison. Note that they are quite specific to our use case which requires a distributed-only (not distributed-replicated) filesystem.
-
How much faster is FhGFS, if at all? FhGFS is about half as fast on identical hardware when doing large streaming writes and reads. However, since even that speed is quite fast, and this is not the predominant operation on the cluster, this is not a fatal flaw. And it is much faster doing small IO. On recursive operations, it is 5-10 times faster, leading to a much better user experience. Since many of our users do interactive work on the gluster filesystem (and a fair number of batch jobs generate or use small files), FhGFS is quite attractive.
-
How hard is it to replace or transition our existing 340TB Gluster system? This would be complex and difficult. Both FhGFS and Gluster have utilities to clear bricks and move files, but even on an Infiniband system, this will take a long time. Our Gluster filesystem is growing very fast so that any transition may be difficult. In the end, we are transitioning the Glfs to FhGFS by transferring the heaviest users to FhGFS first at the same time as reaping old and tiny files from the Glfs. This seems to be working well, if slowly, and the 1st users on the new system are reporting significant speedups, especially among the Image Processing groups and High Throughput Sequencing groups (mostly RNASeq analysis).
-
Can the gluster performance be addressed by hardware upgrades? Not entirely. While the LSI Nytro hardware makes the Gluster fs run quite a lot faster, it does not address all of the recursive lag. Also, re: the point above: How easy is it to transition between hardware upgrades? Even tho LSI now owns 3ware, the 2 controllers use different on-disk formats for their RAIDs; transitioning from a 3ware to an 'LSI’controller will require re-formatting the underlying RAID. This means that we will have to do repeated clear-brick, add-brick operations on 40TB bricks, each one of which will decrease the performance of the filesystem for weeks.
-
What features (beyond performance) does the replacement offer and how well do they work? ie, do the implied features actually work? FhGFS does offer very good performance but actually offers fewer features than Gluster. The FhGFS features that I’ve tried seem to work, although the documentation is sometimes incomplete. The one issue that affects us is the incomplete support for quotas on FhGFS, altho that is supposed to arrive in the next release.
-
What kind of response do we get from support fora and IRCs? Gluster has a definitely advantage here. We have usually gotten very good free online support, from both the Gluster forum and the IRC. There are enough people using Gluster that there are usually a few people who have had the same problem and have either explained it or resolved it. (Particular thanks to Jeff Darcy and Joe Julian for swooping for detailed explanations). The advice from the FhGFS Google group is good - straight from the developers - but the latency can be quite long - up to days before someone responds, tho this has improved considerably lately. Paid support is available from Fraunhofer (email sales@fhgfs.com for specific details) and from RedHat for Gluster (aka Redhat Storage). We recently bought support from fhgfs.com for a small but crucial system and that support has been outstanding.
-
How widespread is the technology and how many people are similarly invested in using it? The FhGFS user base is quite small and I’ve never had a response from another user - only the developers (who certainly know their stuff, but they have other concerns). The FhGFS Google group has ~26 posts for May; the Gluster user base is much larger the posting frequency is larger as well (143 posts in May) and there are many expert users that contribute useful suggestions. It is my impression that the Gluster developer base is much larger and better funded than the FhGFS developer base, which is to be expected for a part of RedHat. However the google search engine returns a surprising number of hits for fraunhofer filesystem (see Table below).
| Search term | # hits |
|---|---|
nfs filesystem |
2.4M |
lustre filesystem |
203K |
gluster filesystem |
190K |
fraunhofer filesystem |
148K |
ceph filesystem |
85K |
The upshot is that while it is an attractive filesystem, and it has been a PITA to transition, the advantage of the FhGFS system under heavy load has proven to be crucial and we are in the process of transitioning. This was mostly enabled by a group buying a large chunk of storage so that we could move data in much larger chunks. Once all the data is moved off the Glfs, it will be converted into another FhGFS. In our hands, FhGFS is a very capable technology and one that is worth examining in more detail if you need a cheap, very fast, distributed-only filesystem that remains performant and reliable under heavy loads.
Gluster has been a remarkably stable system with which we have only a few complaints; small writes, recursive operations chief among them, but the inability to keep up with heavy loads as well as the other irritants have convinced us to convert to FhGFS.
6. Commercial Support
While both Gluster and Fraunhofer are freely available, you can buy commercial support only for FhGFS. Paid support is not available for gluster - only for the RedHat-supported RedHat Storage Server (RHSS). Fraunhofer will support more recent versions of the filesystem with more support for different Linux distributions. Debian and RH variants are supported. I tried mixing them and the installation was surprisingly smooth. Email sales@fhgfs.com for quotes.
Gluster, now that it is a subsidiary of RedHat, uses the RedHat model of support which is less tolerant of alternative distributions - commercial support requires the use of a RedHat-distributed OS/gluster combination that has been tested and approved. This reduces your choices for OS to one (RHEL) and requires that you use the validated (and much older than the current) Gluster release. However, this reduces edge-case bugs, configuration collisions, and whoops events; the assumed preference if you’re looking for commercial support. Call Greg Scott <greg.scott@dlt.com> (Redhat VAR) for a quote.
7. Configuration
7.1. Underlying XFS Fileystems (Storage Servers)
Both Gluster and Fhgfs use standard native Linux filesystems for block-level storage. In both cases, the recommended filesystem is the XFS filesystem from SGI. Like many such filesystems, it has many tunables and these can have a significant impact on performance. This can be seen the results above, especially between the Fhgfs2 and Fhgfs3, the chief differences between which are changes in tuning.
While the man pages for XFS is readily available, they are quite opaque when it comes to actually figuring out what they do and especially how the parameters affect various kinds of IO performance. There are some fairly good non-official guides for configuring XFS, as it applies to various domains. The OSS video recording system MythTV has a very good page on tuning XFS, especially as to the mkfs tunables for video streaming which shares many features with general large file streaming IO. Notably, they include a script for generating tunable variables given your particular hardware.
The mount options that we used for Fhgfs3 largely follow the Fraunhofer storage recommendations. Below is the output from one of our storage server mount commands for the storage RAIDs.
/dev/sdc on /raid1 type xfs (rw,noatime,nodiratime,swalloc,largeio,nobarrier,sunit=512,swidth=8192,allocsize=32m,inode64) /dev/sdd on /raid2 type xfs (rw,noatime,nodiratime,swalloc,largeio,nobarrier,sunit=512,swidth=8192,allocsize=32m,inode64)
7.2. Underlying ext4 Fileystems (Metadata Servers)
Similar to the XFS tunables, the ext4 filesystem can also be tuned for better metadata. Again, our metadata server filesystems were tuned according to the Fraunhfer metadata reommendations. Below is the output from one of our metadata server mount commands for the metadata RAIDs.
/dev/md1 on /fhgfs type ext4 (rw,noatime,nodiratime,user_xattr,barrier=0,data=ordered)
8. Acknowledgements
I thank Ben Smith and Steve Ashauer at LSI for loaning us 2 LSI Nytro 8100 4i SAS controllers for evaluation. Despite my initial misgivings, these controllers are no-brainer upgrades for a heavily used storage servers, be it single RAIDs, a large NFS server or distributed filesystem brick. They are very much worth the small amount of extra money for such a device.
I also thank Dave Hansen and Joe Lipman at Advanced HPC for providing us the flexibilty to test these configurations and for working closely with us to configure and set up these machines. Advanced HPC is one of the few companies that might qualify as a delight to work with.
Thanks to Jeff Darcy of Gluster, Joe Julian (Gluster magician at Ed Wyse Beauty Supply) and Sven Breuner & Bernd Schubert of Fraunhofer for help during setup and comments on this manuscript (tho the remaining errors & sins of omission are mine alone).