1. Faculty Summary
OIT acknowledges that research data is the fuel that drives the university. While recent increases in data growth have outstripped our ability to protect ALL the research data on the HPC cluster, we want to be able to protect that tranche that is deemed most valuable to the HPC users, especially code, reduced data, notes, documents, MD5 checksums, etc. To this end, we will be protecting (less loaded a term than backup) a user-selectable set of data with a minimum quota of 50GigaBytes (GB) for all users' HOME directories and up to 1TeraByte (TB) for those users whose data requirements are larger. Groups will be able to purchase large quotas from OIT to protect more data at a low cost, about 2x the price of raw disk.
This data protection is NOT like your TimeMachine or CrashPlan backups in that we will not protect some files (see below) that are too difficult to transport unless you repackage them. Files are not protected continuously, nor are they guaranteed to be protected at a particular time, nor can you save multiple versions of the files. You will be able to recover your own files in the event of an accidental deletion, but you cannot write to the Protected Storage yourself.
This service is meant to provide an economical, useful level of disaster recovery if a filesystem fails on HPC and to protect against accidental deletion.
2. Introduction and Rationale
The HPC Cluster hosts about 1PB of storage in various pools, chiefly in the 2 BeeGFS distributed filesystems (/dfs1, /dfs2) and the /pub filesystem. Users have been warned continuously and repeatedly that these are scratch filesystems and the data should be considered ephemeral - they could disappear at any time. This has happened - a storage server on the /dfs1 filesystem was disabled due to a disk controller malfunction (altho the data was recovered), a misconfigured script I wrote accidentally deleted a user’s data, and the /pub filesystem was accidentally deleted.
These fairly normal fragilities in the process of day-to-day sysadmin are becoming increasingly dangerous due to:
-
much larger data sets in which all files are important to a particular line of research.
-
the inability to make users understand that their data is their own responsibility and their inability to understand their exposure if they do not back up their data.
-
arguably most important, the demands from grant providers that the data resulting from their funds is maintained in a robust and reliable way, sometimes under penalty of grant clawback if the data cited in resulting papers cannot be produced.
To address these issues, we’ve decided to provide secondary storage to protect at least some of the files stored on HPC. It should not be considered true Backup since due to the size of the system, we cannot afford to back up everything and we cannot guarantee to do it on a daily or even bi-daily basis. We describe the details below, but essentially, we will be protect a quota of storage for every user, then provide rented Protected Storage (ProtStor) for additional files on a $/GB basis.
Since we are very sensitive to price and we are proposing a secondary storage system, not a single primary, we can (and must) use generic storage hardware rather than first-tier products from vendors like EMC and NetApp. These generic but good-quality products can be combined with free softare into a very fast, fairly robust system described below.
3. Overall strategy
Based on the approximate budget of $50K, we have decided to place the ProtStor in the ICS Data Center (ICSDC) to isolate it from the OIT Data Center (OITDC) in case of catastrophe and ICS has already agreed to this.
The transport from HPC to the ProtStor will be over the UCI LightPath 10Gb/s Science DMZ. There are already Lightpath endpoints in the OITDC and ICSDC, so no more building switches nor fiber have to be purchased/installed, except that fiber will have to be pulled internally at ICS to connect the building switch to the servers in the ICSDC.
The ProtStor will consist of a single BeeGFS filesystem of approximately 300-500TB, depending on final costs and requirements. The reason for using a single BeeGFS system instead of multiple stand-alone NFS mounts for the following reasons:
-
BeeGFS provides a single mountpoint and namespace for files (/backup, instead of /backup1, /backup2, /backup3, /backup4, etc), which is much less problematic for any software and load-balancing.
-
BeeGFS is dynamically expandable when we need more space
-
BeeGFS is much faster due to the way storage is striped over multiple arrays and network connections.
-
BeeGFS can run on top of ZFS to co-opt ZFS’s reliability, compression and quota system.
However, BeeGFS is more susceptible to hardware failure since a single controller or even a single array failure can essentially destroy the integrity of most of the data on the BeeGFS system. In a system where each storage server is independent, a similar failure can only affect the arrays on that system.
For example, if we start with ProtStor composed of 2 isolated systems of 3 arrays each: In the case of multiple ZFS volumes, if the controller went bad (as in the case with the infamous LSI Nitro), we would lose all 3 of those arrays, but the other isolated ZFS system would survive. In the less catastrophic case, if 3 disks simultaneously failed in a single array (but the controller continued to work normally), we would lose only that one array’s worth of data. (I have never heard of losing 3 disks simultaneously and only once seen a dual disk failure in my life.)
So while using individual ZFS volumes is more reliable, for us to functionally lose data in that scenario, we would have to lose BOTH the HPC filesystems AND the ProtStor filesystem simultaneously. The probability of that happening are remote (less than Donald Trump being elected).
4. Specifics
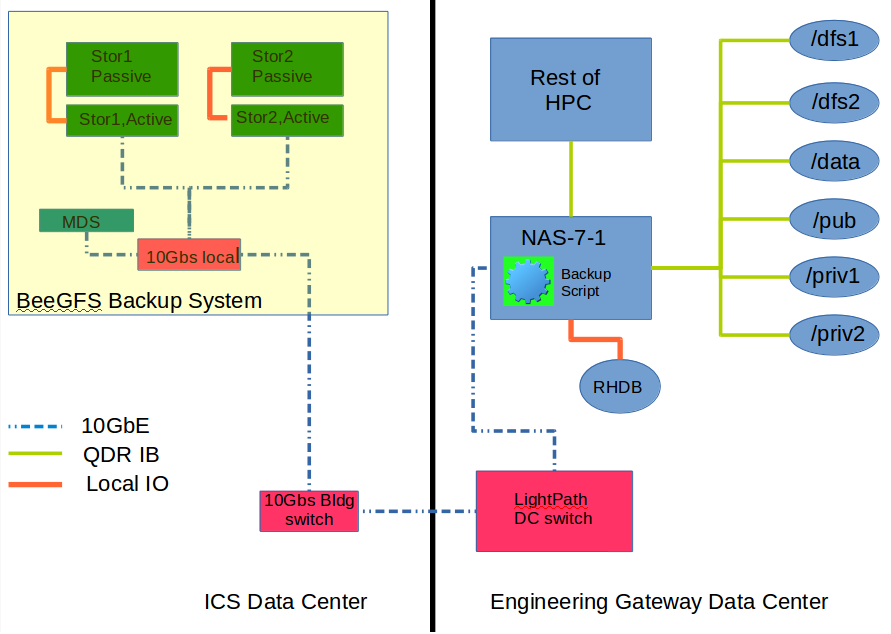
We propose the optimal system will consist of the following components:
-
already have: a recycled HP server for the MetaData Server (MDS) (or we can run the MDS on one of the storage servers).
-
already have: a semi-isolated node on HPC to oversee the file transfer to the ProtStor. This is currently diagrammed as nas-7-1 (the HPC services node), which hosts the RobinHood Database that would be used to filter the files going to the ProtStor. It also is underutilized for its hardware, and is not directly available for public use.
-
possibly need: a small 10Gbs ethernet switch to host the 2-3+ servers that will make up the ProtStor in the ICSDC. This may be avoided if we can direct-attach the servers to the 10Gbs ports on the building switch. All the servers will communicate over 10GbE as opposed to IB for cost reasons (an IB switch would cost an additional $6K). The 10GbE-based system will be somewhat slower than the HPC system, but since it’s only going to be used for ProtStor, it will be fast enough, especially since it will not be hit hard during normal operations.
-
need: at least 2 active storage servers, where active means that they are network-attached multicore storage servers, nearly identical to the ones we currently use on HPC (and for which we already have a spare chassis)
-
possibly need: an additional passive JBOD disk chassis', filled only to the capacity we currently need, but which can be filled with more disks as we need them).
-
need: a fairly simple file transfer script or a customized version of one of the 3 most popular Open Source backup systems (Amanda, Bacula, or BackupPC), almost certainly using a version of rsync, possibly my parallelized version parsync.
-
need: Regardless of where we run the MD server, we will have to buy 4 high performance SSDs (+1 spare) to run in RAID10 for the metadata storage.
-
need: new SPF+-terminated fiber runs from the ICS building switch to the ICSDC.
4.1. Storage server components
| Active Srvs | Passive Srvs | Cost | disks | total | Raw TB ◊ | Usable TB † |
|---|---|---|---|---|---|---|
1 |
0 |
$18.4K |
36 |
36 |
216 |
162 |
1 |
1 |
$36.4K |
36+44 |
80 |
480 |
360 |
2 |
0 |
$36.8K |
36+36 |
72 |
432 |
324 |
2 |
1 |
$54.8K |
(2x36)+44 |
116 |
696 |
522 |
3 |
0 |
$55.2K |
3x36 |
108 |
648 |
486 |
2 |
2 |
$57.4K |
2x36+2x22 |
116 |
696 |
522 ‡ |
2 |
2 |
$72.8K |
2x(36+44) |
160 |
960 |
720 |
◊ with 6TB disks (@ $260ea)
† uncompressed; will gain back to ~raw capacity with ZFS compression
‡ Passive JBODs half-populated
4.2. Other Parts
| # | Description | Needed? | Cost | Total |
|---|---|---|---|---|
5 |
480GB Intel 730 SSD |
Y |
$303 |
$1515 |
1 |
10Gbs SFP+ fiber card |
maybe |
$500 |
$500 |
1 |
8-10port 10Gbs edge switch |
maybe |
$1500 |
$1500 |
3 |
SFP+ fiber; ICS switch to ICSDC |
maybe |
?? |
3x?? |
4.3. Software
We should consider buying support for the BeeGFS. If we run the MDS on a storage node, the cost is about $12K ($6K/server). If we run it on a separate server, it is about $18K. Or we can run without support since we already have support on the main HPC BeeGFS. We also need to decide whether to modify one of the OSS backup systems or to decide if our data movement problem is either so simple or so complex that we need to write our own script.
5. Backup Rules
This ProtStor is not meant to be a complete backup; certainly not an archiving system, so rules have to be set to determine what gets backed up.
Here are some rules that we’ve discussed with some limits that I’ve calculated based on current HPC storage use.
-
all of /data gets backed every day (currently backed up 2x already). This contributes a total of about 5.2TB files
-
/data includes the 50GB hard limit of user files, as well as all the cluster configuration files, documentation, applications, and common data.
-
for the rest of the filesystems, we set an XXTB limit for every user. If we set it to 1TB/user, the ProtStor system will have to be at least 140TB. If we set it to 2TB/user, then the size increases to 170TB. We should also include a substantial amount of spare storage for emergency buffering and common data to get it off /data.
-
the above includes /pub (which allows some users to inflate their backed-up files to 4TB, if they’re sneaky).
-
the ProtStor is READ-ONLY for users. Users cannot write directly to the ProtStor themselves.
-
the files must reside on HPC to remain on the ProtStor system within a certain period of time.
-
This is to prevent the ProtStor from acting as remote active storage. (ie. if a file is deleted from the HPC filesystem, it will be deleted from the ProtStor filesystem after a period of XX days) to prevent aggregating files to the backup that they’re not using.
-
files that are detected on ProtStor that aren’t on HPC will trigger email to the users telling them that this has happened and that they will have XX days to recover it or it will be deleted on the ProtStor side.
-
-
files on private storage servers inside of the HPC private network can be backed up to the user limit. (good idea?). ie: if a group bought a server internal storage, the users can indicate that they want that storage backed up to the overall limit of XX TBs/user on the ProtStor.
-
users and groups can purchase more storage on the ProtStor for a $150/TB/3yrs.
-
when the quota for the user has been exceeded on the ProtStor, the backup of their files stops immediately and email is sent to the user to warn them that their ProtStor quota has been exceeded.
5.1. Security
-
the ProtStor will not be available generally at all to HPC users as a security measure (thanks Garr). If it was, in the event of an encryption attack, it would be encrypted as well. To protect against this, the ProtStor will only be available from certain transfer nodes and only when the transfer jobs were running. As soon as they were finished, the ProtStor would be unmounted from HPC.
-
it might even be worthwhile to have an entirely separate transfer node that mounted HPC READ-ONLY and mounted ProtStor READ/WRITE to further isolate the process. This would require an additional dual-port 10GbE copper card (if in the OITDC) in one of the HP DL360 servers.
-
users who request dirs on the ProtStor to be deleted or files to be restored will have to request them by email or web form and that will trigger a re-mount when the operations are pooled and executed.
5.2. Omitted files
In NO cases will we back up:
-
ZOTdirs, defined as those dirs which have more than X,000 files in them.
-
zero-length files
-
coredump files
-
files on any explicitly /scratch, /tmp, or /checkpoint dirs.
-
SGE output/error files
-
remote mounts (file remotely accessed from Google drive, personal laptops, desktops, etc). The files must reside on an HPC filesystem.
5.3. Reaping
There should be a mechanism by which the ProtStor filesystem is continually reaped or cleaned.
-
if a user leaves UCI, how long should their data remain on the ProtStor?
-
even if a user remains at UCI, what is the maximum age that files should be allowed to remain on the ProtStor system? Or even the HPC public systems? (User data on private systems can remain indefinitely).
-
should users be allowed to specify which dirs on the ProtStor should be deleted by filling out a web form or emailing us? Since it’s READONLY, they can’t do it themselves.
5.4. User-level Guidance
Users should tell us which dirs to back up and which ones to ignore. We will assume that everything is to be backed up (mod the exceptions listed above), unless the quota is exceeded. If it is, then we will be guided by modifying a ~/.backup.exclude file that describes dirs and files to be excluded. This allows subfiltering of dirs so you could back up all of ~/mydata/2016, but not ~/mydata/2016/June. This file should also be able to exclude files and dirs based on regular expressions, essentially identical to the --exclude-from file that tar and and rsync support.
6. Initial Fill and Cycle Time.
Based on some quick tests of the system while it was under load (see Figure 2 below), we will see about 400-600MB/s writing to the ProtStor. This is considerably less than the max observed when I was transferring data from Gluster to BeeGFS since the Gluster nodes were writing directly, and the BeeGFS was otherwise idle. So the bandwidth that we can expect to see is almost 10x less than that max.
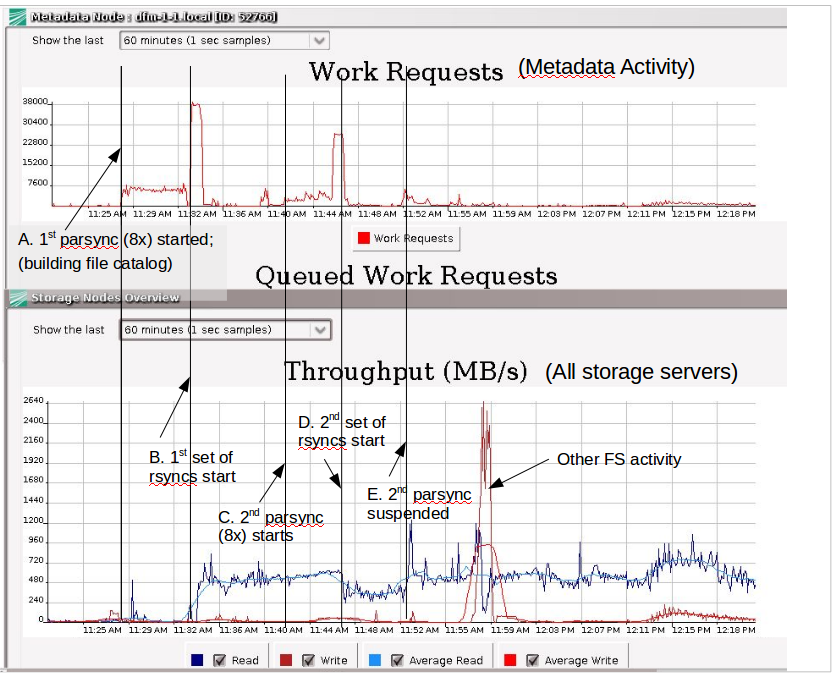
Due to that bottleneck, it will take about 4-6 days to initially populate the ProtStor, after which the incremental speed will be fairly fast. We probably could do daily backups if we needed to, but since we only RobinHood-scan the HPC filesystems once a week, a 1x week backup might be OK. We could also charge for more frequent backups, launching specific parsyncs at user/group dirs.
Garr is querying the RHDB to see what the file change churn is so we can get an idea of how fast the incremental time is.