1. Acknowledgements
Thanks to Thomas Cheatham <tec3@utah.edu> and Brian Haymore <brian.haymore@utah.edu> at the Center for High Performance Computing) at the Univ of Utah for directing me to rclone on the XSEDE Campus Champions list and providing corrections and missing information to this document, tho remaining errors are mine. Also thanks to Vikram Gazula <vgazu2@uky.edu> at the Univ of Kentucky for providing hints about optimal use of rclone. Much appreciated.
2. Introduction
You can attach your Google Drive to the HPC cluster as described here. However, while the convenience is good, the bandwidth is pretty bad - on the order of 3-5MB/s.
Below, I show how to push data back and forth to your Google Drive (or Google Storage or Amazon S3) at much higher rates using rclone. You can still access your files on HPC via the mechanism described above, but the bulk movement of data can go much faster, enough to use your Google Drive as a functional backup to your data on HPC, if formatted correctly.
Note that your interaction with Google Drive as described above and your interaction with it via rclone is independent. You can refer to and manipulate files via rclone without a Google Drive mount on the HPC Cluster and vice versa. Similarly, if you are interacting via both mechanisms simultaneously, there will usually be a short delay as the updates propagate thru the system.
|
|
Object storage vs POSIX Filesystems
Google Drive and Amazon S3 are not file systems as you normally think of them (if you thought of filesystems at all). While they store files and you can make directories, the underlying storage is an object store - a technology derived from the web which is great for storing large numbers of unrelated file objects and retrieving them fairly quickly. While many object stores have what’s called a POSIX layer on top to fake being a normal filesystem, object filesystems are really good at some things and (currently) fairly poor at others. Here’s a more extensive description of the differences. Also, once your files are on the remote cloud storage, unless it’s on a pretty good POSIX emulation, you won’t be able to do some things you be able to on your own laptop. Also, unless you spin up a remote, cloud-based Virtual Machine (VM) and point it at your storage, you won’t be able to do some useful things to your remote files, like unzipping/untarring them, and especially, rsyncing them. |
There are some GOTCHA’s. In order to maximize your bandwidth, you’ll have to move lots of data at once, in parallel, optimally organized as multi-GB files. Also, Google Drive only allows 2 files/sec to enter or leave their storage cloud, so if you’re trying to transfer unmodified ZOTfiles, you’ll be waiting a long, long time.
|
|
Google Drive is not Google Storage.
Your UCI Google Drive is free but there is no such agreement for Google Cloud Storage. Drive is built on Google’s Storage platform, but has some different semantics and is certainly licensed & monetized differently. |
UCI’s agreement with Google gives every UCI-affiliated person 10TB of space on Google Drive. In fact, that limit is not (currently) enforced; I have pushed 125TB to my own Google Drive without objection (yet) from Google. The problem with that agreement is that the speed at which you can push the data is very low - on the order of 2-5MB/s, via normal connections.
Since we now have a 10Gb/s interface to our high-speed research DMZ (aka Lightpath), we can exploit that high-speed connection to UCI’s Internet Service Provider (ISP) CENIC to enable data transfers to Google Drive at much higher speeds with a fairly new utility called rclone that can increase bandwidth dramatically.
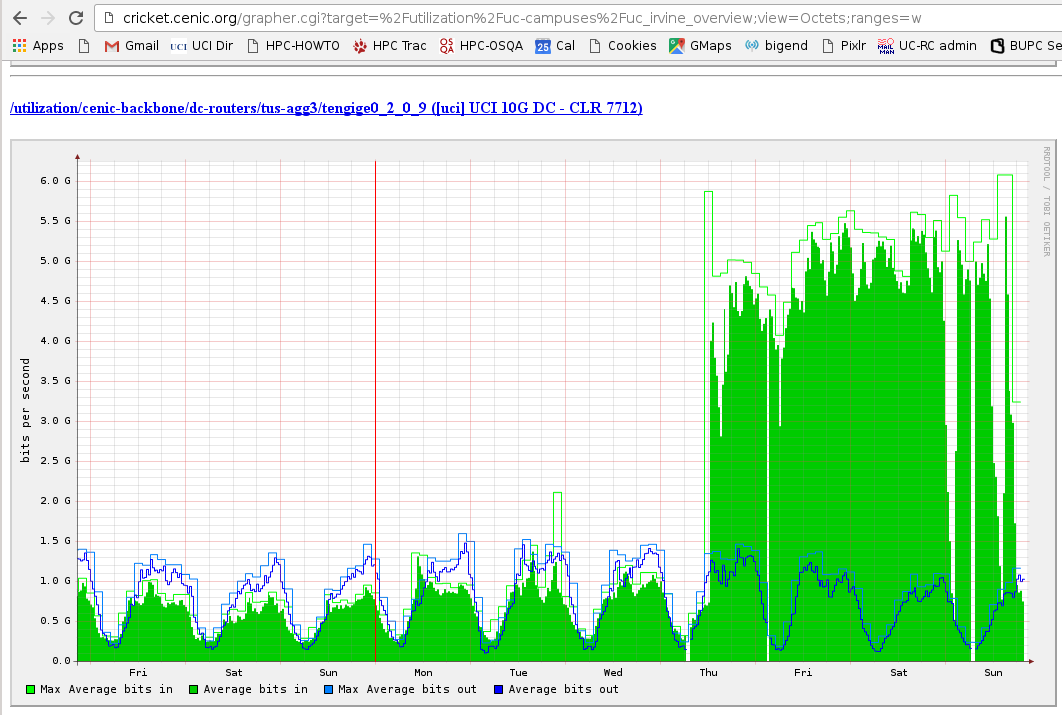
3. rclone
rclone is written in Google’s Go Language, sort of a cloud version of rsync and is installed on HPC for everyone to use. It requires you to set up an authentication with Google (or other cloud service) prior to the data transfer and thereafter maintains that authentication in your %7e/.rclone.conf file. DO NOT LEAVE THIS FILE READABLE BY OTHERS.
Use of rclone is surprisingly straightforward for the amount of under-the-covers authentication it does and supports not only Google Drive, but also Amazon Web Services and a number of other cloud service providers.
3.1. rclone configuration
-
in order to exploit the high speed connection, you need to be logged into the HPC Lightpath node, compute-1-13. This is also known as our interactive node, and is the default endpoint for the qrsh command. So, from any login node, qrsh will connect you to compute-1-13.
-
start HPC’s firefox via x2go, log into your UCI account at Google (for example by logging into your Gmail account)
-
You should now have a bash shell as well as the firefox browser open. If you cannot open firefox, a text-mode browser like lynx may work as well, since it only has to return an alphabetic string.
The following is an annotated transcript of the rclone config command.
## - these are my annotations ## start the rclone configuration $ clone config ## lists my current 'remotes', currently a Google Drive and a Google ## Cloud Storage object Current remotes: Name Type ==== ==== gdrivefs drive google-dra google cloud storage e) Edit existing remote n) New remote d) Delete remote s) Set configuration password q) Quit config e/n/d/s/q> n name> gdrv ##<<< new object name ## I'm going to initialize a new Google Drive object called 'gdrv'. ## Your Drive object can be called anything convenient. Type of storage to configure. Choose a number from below, or type in your own value 1 / Amazon Cloud Drive \ "amazon cloud drive" 2 / Amazon S3 (also Dreamhost, Ceph) \ "s3" 3 / Backblaze B2 \ "b2" 4 / Dropbox \ "dropbox" 5 / Google Cloud Storage (this is not Google Drive) \ "google cloud storage" 6 / Google Drive #<<< this is what we want \ "drive" 7 / Hubic \ "hubic" 8 / Local Disk \ "local" 9 / Microsoft OneDrive \ "onedrive" 10 / Openstack Swift (Rackspace Cloud Files, Memset Memstore, OVH) \ "swift" 11 / Yandex Disk \ "yandex" Storage> 6 ## <<<'6' is the selection to choose a Google Drive Object. Google Application Client Id - leave blank normally. client_id> ## safe to leave it blank unless you know that it should be something else. Google Application Client Secret - leave blank normally. client_secret> ## as above. Remote config Use auto config? * Say Y if not sure * Say N if you are working on a remote or headless machine or Y did not work y) Yes n) No y/n> y ## if you have opened firefox, choose 'Y', if you can't, choose 'N' and ## then you'll have to open a /local/ browser and paste in a link that ## will generated for you. If your browser does not open automatically go to the following link: http://127.0.0.1:53682/auth ## you may have to paste this link into the firefox browser. Log in and authorize rclone for access Waiting for code... Got code -------------------- [gdrv] client_id = client_secret = token = {"access_token":"ya29.CjHh7oWT..._BG2E...wcfgFqLtsPk....qwx52X..sLtXviQWf","token_type":"Bearer","refresh_token":"1/L9WR5Z-...9efOW7UkdP...D_S.U4YI","expiry":"2016-05-13T17:54:09.173009523-07:00"} -------------------- y) Yes this is OK e) Edit this remote d) Delete this remote y/e/d> y ## this should be the end of the auth process. Now rclone will show you all your 'remotes', ## including your new one. Current remotes: Name Type ==== ==== gdrivefs drive gdrv drive ##<<< Here's the new one I just authorized. google-dra google cloud storage ## Note that both 'gdrivefs' and 'gdrv' point to the same Google Drive storage; ## they're just different handles to the same thing ## If you have a personal Google Drive account as well as a UCI Google Drive, ## you can authorize them separately - just be sure to name them differently e) Edit existing remote n) New remote d) Delete remote s) Set configuration password q) Quit config e/n/d/s/q> q ## [back to prompt]
So now you’re ready to go with the remote that you just enabled. You may be able to interact with all the remotes listed, but you’ll have to make sure that you’re authorized with all of them.
I reference my Google Drive as gdrv in rclone, with directories specified after a : ie:
gdrv:remote_dir
so in order to see what’s on my Google Drive via rclone, I’d type:
$ rclone lsd gdrv: ## and I get the following: -1 2016-05-05 19:39:47 -1 fabio -1 2016-05-04 04:22:19 -1 allTs -1 2015-12-04 23:44:39 -1 commondata -1 2014-12-12 22:46:12 -1 Spoons-Dec-2014 -1 2014-12-12 22:45:02 -1 boards
BE CAREFUL: ls and lsd are VERY different commands. rclone ls will recursively list ALL files on your gdrive, which, if you’ve pushed 120TB of files, may be a very large list. rclone lsd remote: will list only the immediate directories.
Further explicit recursion is possible: for example:
$ rclone ls gdrv:boards/sayas ## lists all the files (images) I have in the directory boards/sayas 3428416 IMG_3263.JPG 4850137 IMG_3262.JPG ... 1933686 IMAG0957.jpg 2803662 IMAG1208.jpg
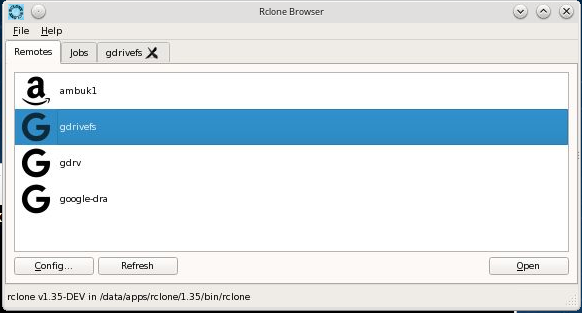
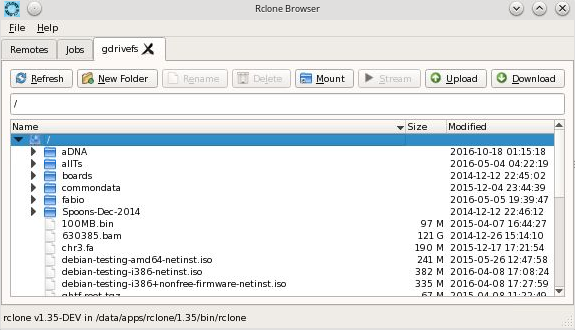
4. rclone-browser
rclone-browser is Qt-based wrapper around rclone which makes it much easier to view and select files to push and pull.
You still have to go thru a TERMINAL-based configuration sequence as above to add new Remotes but once that’s done, it provides a File Browser-like interface to moving files back and forth.
5. Remote Pattern Matching
If you’re coming from the Linux world, you will expect to be able to select files via globbing. rclone supports glob-like regular expression (regex) pattern matching, but you can’t do "normal" globbing selection with rclone, altho it does allow the use of globby-like filters which allow you to do a similar kind of filename pattern matching. However you have to format the glob differently than you normally would in a bash or grep regex.
For example, I have image files with suffixes of both .jpg and .JPG in my gdrv:boards/sayas dir. If I wanted to list only the ones ending in .jpg in bash, I would use the familiar construction:
$ ls ~/boards/sayas/*.jpg
In rclone, you have to separate the regex from the remote:dir specification:
$ rclone ls gdrv:boards/sayas --include "*.jpg" # or $ rclone --include "*.jpg" ls gdrv:boards/sayas ## ie the 'include' option can precede or follow the 'ls' spec $ rclone --include "IMAG1*.jpg" ls gdrv:boards/sayas 2548895 IMAG1211.jpg 2806346 IMAG1210.jpg 2126769 IMAG1209.jpg 2571693 IMAG1180.jpg 2630832 IMAG1179.jpg 1561308 IMAG1178.jpg 2803662 IMAG1208.jpg
6. Push data TO Google Drive.
To put data into your Drive using rclone, you use the copy command. Initially, try it by itself:
$ ls -l out -rw-r--r-- 1 hmangala staff 4.0M Feb 7 16:50 out ## ^^^^ only 4MB $ rclone copy out gdrv: 2016/05/16 12:00:59 Google drive root '': Building file list 2016/05/16 12:01:59 Transferred: 0 Bytes ( 0.00 kByte/s) Errors: 0 Checks: 0 Transferred: 0 Elapsed time: 1m0.3s 2016/05/16 12:02:08 Google drive root '': Waiting for checks to finish 2016/05/16 12:02:08 Google drive root '': Waiting for transfers to finish Transferred: 4144710 Bytes ( 57.20 kByte/s) Errors: 0 Checks: 0 Transferred: 1 Elapsed time: 1m10.7s
so to copy a 4MB file to Drive took 70s or 0.06MB/s, pitifully slow. A larger (25MB) file takes 2m23s or 0.17MB/s, better but barely. This reflects the large amount of overhead that such transfers take on a single transfer. For a much larger file (1.7GB), the instantaneous transfer tops out at a much better 17MB/s (with the average dropping to about 10MB/s, counting the initiation/termination overhead), but that is about the max that you’ll see on a single file transfer.
To obtain good transfer rates, you have to increase the number and size of files you transfer at one time, as well as the number of simultaneous streams and the checkers (the processes that are checking the streams).
For example, if I have 64x 10GB files (626GB) to transfer in parallel, using an increased number of both streams and checkers, I can dramatically increase the bandwidth:
$ rclone --transfers=32 --checkers=16 --drive-chunk-size=16384k \ --drive-upload-cutoff=16384k copy /som/hmangala/10g gdrv:10GB_files ... 2016/05/16 12:51:59 Transferred: 193919451136 Bytes (390809.91 kByte/s) Errors: 0 Checks: 0 Transferred: 0 Elapsed time: 8m4.5s Transferring: * fb_3: 57% done. avg: 12334.0, cur: 9262.4 kByte/s. ETA: 7m49s * fb_4: 59% done. avg: 12847.5, cur: 10496.4 kByte/s. ETA: 6m31s ... excludes 28 other simultaneous transfers * fb_60: 55% done. avg: 11943.4, cur: 10357.7 kByte/s. ETA: 7m17s * fb_62: 58% done. avg: 12632.4, cur: 10729.2 kByte/s. ETA: 6m32s # and finally, it finishes with: Transferred: 671744000025 Bytes (283062.68 kByte/s) Errors: 0 Checks: 60 Transferred: 70 Elapsed time: 38m37.5s
So, for rclone to transfer files efficiently, there has to be a large payload per transfer and a number of simultaneous streams. It works best if there are large, identically sized files, but regardless, larger files are better, because of the initiation overhead.
7. Pull data FROM Google Drive
The reverse mechanism - retrieving data from your Drive repository is essentially identical, with the source and target swapped:
## if a remote dir structure was: $ rclone size gdrv:boards/saladscoops Total objects: 24 Total size: 70.774M (74212429 bytes) ## so 24 files/dirs totaling 71MB and I wanted to copy it all down to ## my local machine, I would issue: $ mkdir pix ## create a dir to hold the downloaded pics. $ rclone --transfers=12 copy gdrv:boards/saladscoops pix 2016/05/18 10:41:47 Local file system at /data/users/hmangala/pix: Building file list 2016/05/18 10:41:48 Local file system at /data/users/hmangala/pix: Waiting for checks to finish 2016/05/18 10:41:48 Local file system at /data/users/hmangala/pix: Waiting for transfers to finish Transferred: 74212429 Bytes (10028.39 kByte/s) Errors: 0 Checks: 0 Transferred: 24 Elapsed time: 7.2s ## not great bandwidth, but for such a small set of data...
8. Access to Shared Drives
I didn’t think this could be done, but a need for sequence that had been stored on a Google Drive pushed me to try it. I suspect that the sharing was set up promiscuously (Share with anyone at blah who has this link) and if done correctly (Share only with these people), I would not have been able to do this. Nevertheless…
8.1. The background
A grad student had obtained a sequencing set of a couple hundred GB, had backed it up on a shared Google Drive to which the PI had shared access. The GS then went incommunicado. The PI had tried downloading to her Mac via wifi over the commodity Internet, which did not end well. She needed the dataset on our HPC cluster for analysis and I ended up in the mix.
8.2. The Solution
I updated rclone and rclone-browser on the cluster, and tried to use the link to the shared Google Drive to convince rclone to show me the data but that was a dead end. The link looks like this:
https://drive.google.com/drive/folders/1zsM9pKtdXJ.....VAWDSG2zA985
and that hash is irreversible of course. I thought there might be a way to insert it into the rclone config file, but that also led to madness.
However, Google Drive now has a mechanism to link Shared with me drives in your My Drive view from the web interface.
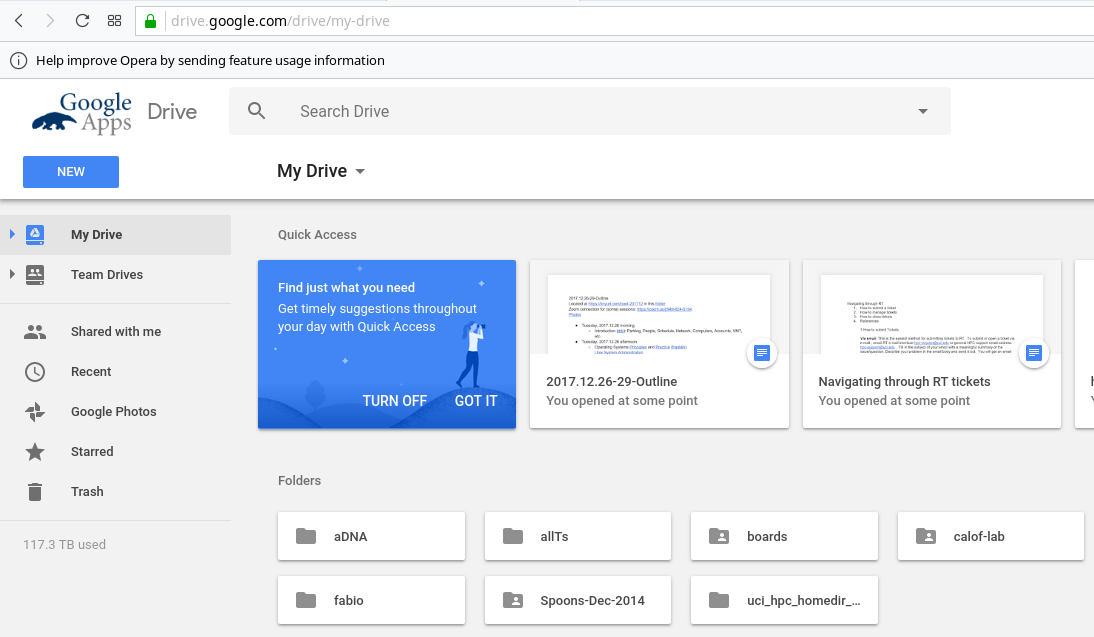
This is the Google Drive folder that was shared with me:
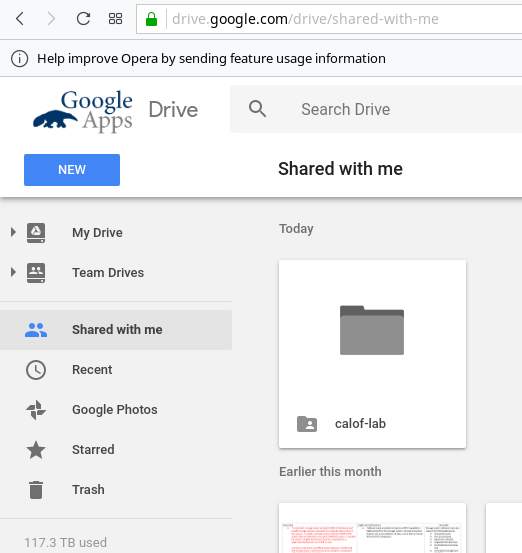
I was able to right-click on the folder and select Add to My Drive, which now adds a symlink to My Drive so I can see 'calof-lab in the same level as other top-level folders:
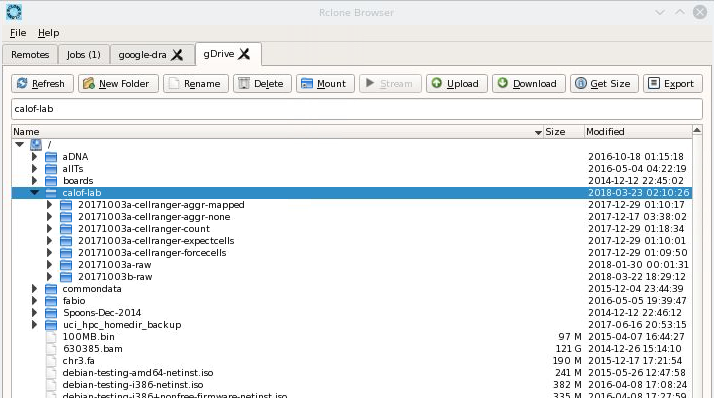
Here’s the view from the rclone-browser now:
 .
.
Note that it also shows up with the commandline rclone:
hmangala@nas-7-1:~
1034 $ rclone-new --drive-shared-with-me lsd gdrv:
-1 2016-09-16 04:58:01 -1 CC_2016
-1 2017-09-19 19:39:23 -1 MCSB Bootcamp 2017
-1 2016-08-30 17:13:13 -1 RCS??RCIC Management
-1 2018-03-15 04:31:31 -1 UC-Wide Research IT Meetings
-1 2018-03-05 18:20:51 -1 Vendor Quotes 2016-2017
-1 2018-03-23 02:10:26 -1 calof-lab <-------- !!
From there, it’s just a matter of selecting the correct folder in the rclone-browser and clicking Download or optimizing the download with commandline rclone. On our 10GbE LightPath DMZ connection, the sequence files came down at >10GB/m, but then slowed waaayyyyyyy down when the small analysis files were hit. It looks like it’s finishing off at 0.2 KB/s. Ugh. But possible.
The limits on Google Drive upload and download limits are unclear. I’ve seen 750GB/day mentioned, but have also seen others and was personally able to transfer about 100TB (incl. files >100GB) over a weekend, tho I am covered under an academic agreement that may be more flexible. Here’s one thread that includes an (unofficial) take from a purported Google Engineer. There does not seem to be a download limit that I should have hit, but there was a very long tail to completion.
9. File administration on the remote end
rclone also supports manipulation of the files on the remotes. None of these commands are as easy or as fast as manipulating a local file, but if you have to interact with a remote file objects, they are usable.
Please see the rclone usage documentation for how to use rclone for remote file admin.
10. Balanced upload and remote pull-apart
…not about pastries, but about how to automate the upload and remote use of uploaded files. Because rclone needs many, large, identically-sized files to upload for best bandwidth utilization, it would be useful to design a script that would do this automatically for a given starting set of files and dirs.
There is a very good, portable utility called fpart that will recursively aggregate files into groups by size or number for feeding into other utilities', so the sending is not the problem. The problem is in the use at the remote end. Local files end up as partially split aggregates or approximately same-sized tar files remotely, and there does not seem to be a utility as part of Google Drive. There may be a second source - Drive Unzip that allows the remote pulling apart of such files. The only other mechanism of doing so seems to be to spin up a Google VM to manipulate the data on the remote end or use a Google API to do the same, as Drive Unzip may have done.
If anyone else has a good idea of how to do this, please let me know.