|
|
Request for feedback
clusterfork was designed for myself, but has been in daily use for 5 years at our cluster. If you think it could benefit from other options or interface tweaks, please let me know. |
1. Availability
clusterfork is released under the Free Software Foundation’s Affero General Public License (GPL) version 3.
The Perl code is available here.
2. Introduction
While modern cluster technologies (Perceus, Warewulf, ROCKS) should obviate the need for this kind of utility, there are many non-Perceus/WW/ROCKS clusters and even more cluster-like aggregations of nodes that often need this kind of tool. Even in Perceus/WW/ROCKS clusters there’s often the need to issue a command to each node to evaluate hardware, search logs, determine memory errors, etc that is not met by the provisioning system.
3. Features
Why use clusterfork rather than the tools noted below?
clusterfork:
-
is config file-based (and will write an example template if one doesn’t exist). You can also specify alternative config files.
-
has an easy way to specify large, discontinuous IP# ranges with negations: ie 128.200.34.[23:45 -25 77:155 -100:-120] will send the cmd to the nodes (on net 128.200.34.0) 23 to 45 EXCEPT 25 and then 77 to 155 EXCEPT the nodes 100 to 120. Such specifications can also be chained or instantiated in the config file. See Specifying Ranges below.
-
config file can specify IP ranges based on arbitrary scripts such as SGE’s qhost.
-
can combine IP ranges into larger groups via named group addition (GRP1 + GRP2 + GRP3)
-
is pretty fast (by default, forks commands so that they execute in parallel).
-
comes with at least a decent amount of documentation, both external (this file) as well as internal help (clusterfork -h)
-
code is short (<1400LoC, including rc file template and help text), pretty well-documented and easy to modify.
-
provides a mechanism to evaluate the results of the command (like pssh, but better).
-
can archive the results, altho in a fairly primitive way.
-
will filter which IP #s overlap in a command so nodes won’t receive multiple copies of commands.
-
provides multiple mechanisms for showing results: MD5 hash and wordcount of machine-specific output to show both exact and similar output, as well as saving the output for later perusal in a newly created subdir which also contains a summary file. You can view the output as a summary, or via Midnight Commander browsing of the results dir.
-
captures STDERR as well as STDOUT into the node-specific results files.
-
tracks running hosts to identify hung or trailing hosts.
-
can be config’ed to write results files to a specific dir or in the current dir
-
will delete empty results files before presenting them for evaluation (but note them in the Summary).
-
can be scripted to log the usual output, returning the results directory so that the execution results can be evaluated programmatically.
4. Prerequisites
Note that it does have a few Perl dependencies beyond the usual strict and Env:
-
Getopt::Long to process options
-
Config::Simple to process the configuration file.
-
Socket to provide hostname resolution.
It also requires some apps that are usually installed on most Linux boxen anyway.:
-
ssh for executing the commands (and obviously the nodes have to share ssh keys to provide passwordless ssh)
-
mutt, for emailing out notifications (if desired)
-
diff, for doing comparisons between files of IP #s
-
yum or apt-get if you want to use it for updating / installing apps.
-
mc (Midnight Commander) a Norton Commander-like clone to view/manipulate files - this is extremely useful for browsing the results of the command. It may have to be configured to list files in the left pane and the view in the right pane for the best result.
-
whatever local apps, scripts, etc that you need to use to generate IP# lists if this is of interest (SGE’s qhost to see what nodes are alive, for example).
5. Installation
for recent Ubuntu-based distros, the following will install the prerequisite packages.
sudo apt-get install libgetopt-mixed-perl libconfig-simple-perl \ libio-interface-perl mc diff yum apt mutt
for CentOS5 and comparable RedHat based systems:
ARCH=`uname -a |cut -f 12 -d ' '`
if [[ ${ARCH} =~ 64 ]]; then ARCH="x86_64"; else ARCH="x86"; fi
sudo yum install perl-Config-Simple.noarch perl-Getopt-Mixed.noarch \
perl-Config-Simple.noarch perl-IO-Interface.$ARCH mc.$ARCH \
diffutils.$ARCH yum.noarch mutt.$ARCH
where $ARCH is either x86 or x86_64 if not set by the above query.
Beyond that, the installation requires:
-
downloading the clusterfork script itself.
-
move it to your /usr/local/bin as clusterfork (and optionally, symlink it to cf)
-
chmod it to make it executable
-
run it once to write a .clusterforkrc file to your $HOME (see below).
-
edit that file to adjust it to your local requirements
-
start clusterforking.
6. Initialization
The 1st time you use clusterfork, you should get this message (unless you’ve already copied a ~.clusterforkrc file from somewhere else). Just follow the instructions.
$ clusterfork
It looks like this is the 1st time you've run clusterfork
as this user on this system. An example .clusterforkrc file
will be written to your home dir. Once you edit it to your
specifications, run a non-destructive command with it
(ie 'ls -lSh') to make sure it's working and examine the output
so that you understand the workflow and the output.
Remember that in order for clusterfork to work, passwordless ssh keys
must be operational from the node where you execute clusterfork to the
client nodes. If you're going to use sudo to execute clusterfork, the
root user public ssh key must be shared out to the clients.
Typical cluster use implies a shared /home file system which means that
the shared keys should only have to be installed once in
/home/$USER/.ssh/authorized_keys.
Please edit the ~/.clusterforkrc template that's just been written so that
the next time things go smoother.
7. The .clusterforkrc configuration file
The .clusterforkrc config file (by default in your $HOME) is arranged like a Windows .INI file with stanza headers indicated with [STANZA]. Each stanza can have an arbitrary number of entries, but only the stanzas shown are supported by cf. Nothing prevents you from adding more, but you’ll have to process them yourself. Within each stanza, you can edit the entries
The stanzas named [IPRANGE] and [GROUPS] can be expanded arbitarily and cf should pick them up. Additionally, if you specify groups which have overlapping IP ranges, cf will detect that overlap and will only issue the command once per IP #.
# This is the config file for the 'clusterfork' application (aka cf) which executes
# commands on a range of machines defined as below. Use 'clusterfork -h'
# to view the help file
# Comments start with a pound ('#') sign and //cannot share the same line//
# with other configuration data.
# Strings do not need to be quoted unles they contain commas (imply list entries)
[ADMIN]
# RPMDB - file that lists the RPMs that cf has been used to install
RPMDB = /home/hmangala/BDUC_RPM_LIST.DB
# ALLNODESFILE holds a list of ALL the IP nodes that this will support.
# this should actually be generated outside of cf and written out if required.
ALLNODESFILE = /home/hmangala/ALLNODESFILE
# emails to notify of newly installed packages (note the escaping of the '@'
EMAIL_LIST = "hmangala\@uci.edu, jsaska\@uci.edu, lopez\@uci.edu"
# how many IP addresses to list on a line - 5 is pretty good.
IPLISTWIDTH = 5
# write all the results in this dir; comment out or assign to "" if you
# want to write the results in the current working dir.
# use fully qualified path; not '~/cf'.
RESULTS_DIR = "/home/hmangala/cf"
# command to install apps - if this is found in the command, triggers a routine to
# email admins with updated install info.
INSTALLCMD = "yum install -y"
[SGE]
# obviously only applies if you're running an SunGridEngine instance
CELL = bduc_nacs
JOB_DIR = /sge62/bduc_nacs/spool/qmaster/jobs
EXECD_PORT = 537
QMASTER_PORT = 536
ROOT = /sge62
[APPS]
# these will probably not change much among distros, but YMMV
yum = /usr/bin/yum
diff = /usr/bin/diff
mutt = /usr/bin/mutt
mc = /usr/bin/mc
[IPRANGE]
# you //definitely// need to change these.
# use ';' as separators, not commas. Spaces are ignored.
ADC_2X = 10.255.78.[10:22 26 35:49] ; 10.255.78.[77:90] ; 12.23.34.[13:25 33:44 56:75]
ADC_4X = 10.255.78.[50:76]
ICS_2X = 10.255.89.[5:44]
CLAWS = 10.255.78.[5:9]
# example of mixing IP# ranges and both single hostanems and hostname ranges
MIXED = a64-[002:004] ; 10.255.78.16; 10.255.78.[10:12] ; dabrick ; claw[5:9]
# for a definition based on a script, the value must be in the form of:
# [SCRIPT:"whatever the script is"]
# with required escaping being embedded in the submitted script
# (see below for an example in QHOST)
# the following QHOST example uses the host-local SGE 'qhost' and 'scut' utilities
# to generate a list of hosts to process and filters only 'a64' hosts
# which are responsive (don't have ' - ' entries). Returns the list as
# a space-delimited set of names.
QHOST = SCRIPT:"qhost |grep a64 | grep -v ' - ' | scut --c1=0 | perl -e 's/\\n/ /gi' -p"
# Set temporarily dead nodes in here if required. Keep the "", if no values to insert.
# separate hostnames or ranges with ';' as above.
IGNORE = "10.255.78.12 ; 10.255.78.48 ; 12.23.34.[22:25]"
# or
IGNORE = ""
[GROUPS]
# GROUPS can be composed of primary IPRANGE groups as well as other
# GROUP groups as long as they have been previously defined.
ALL_2X = ICS_2X + ADC_2X
CENTOS = ICS_2X + ADC_2X + ADC_4X
ADC_ALL = ALL_2X + ADC_4X + CLAWS
8. Specifying Ranges
The range specifier in cf is fairly flexible (mostly taken from the slice’n'dice utility scut). You can specify the target ranges with either IP #s (128.200.15.[34:88 -55]) or alphnumeric hostnames (node_[211-345 -255:-258].somenet.podunk.edu).
BUT only 1 variable specification per hostname string, please (don’t try cn_[45:299].net-[23:35].podunk.edu; you’ll regret it.)
Also, if the 1st number is entered using leading/padding zeros, the numbers emitted will also have the same number of characters. For example, [0005:0023] will generate 0005 0006 0007 … 0022 0023, as will [0005:23] - it’s just the 1st number that sets the pad length.
You can also chain specifications like this: (taken from an example ~/.clusterforkrc file).
# ADC_2X can be specified either with a central negation range:
ADC_2X = a64-[104:181 -141:-167]
# or as this a chain of 2 separated ranges
# (you must use a ';' as a chain character)
ADC_2X = a64-[104:140] ; a64-[168:181]
# you can also specify hostgroups with chains of mixed IP #s and hostnames
# they should resolve to each other and both are listed on output
BOOBOO = 10.255.78.[22:46] ; a64-[168:177]
8.1. Specifying Individual Hosts
You can also specify a few hosts to target without doing any complicated ranges, by using the --hosts option. Appending the hostnames or IP #s to this option will allow you target a few specific hosts more easily. See Options below. remember to quote the string and only use whitespace between the names.
ie:
cf --hosts='nina pinta santa_maria enterprise exxon_valdez'
9. Options
The options are spelled out fairly well by the cf -h command. However, here they are again, verbatim.
--help / -h............. dump usage, tips
--version / -v ......... dump version #
--config=/alt/config/file .. an alternative config file.
On 1st execution, clusterfork will write a template config file
to ~/.clusterforkrc and exit. You must edit the template to
provide parameters for your particular setup.
--target=[quoted IP_Range or predefined GROUP name]
where IP_Range -> 12.23.23.[27:45 -33 54:88]
or 'a64-[00023:35 -25:-28].bduc'
(Note that leading zeros in the FIRST range specifier will be
replicated in the output; the above pattern will generate:
a64-00023.bduc, a64-00024.bduc, a64-00029.bduc, etc)
where GROUP -> 'ICS_2X,ADC_4X,CLAWS' (from config file)
(see docs for longer exposition on IP_Ranges and GROUP definition)
--hosts=[quoted space-delimited hostnames]
For those times when you have a random number of hostnames to send.
ie: --hosts='a64-111 a64-142 a64-183 a64-972'. This will process
them in the same way as '--target' above, but without having to spec
the ranges.
--delay=# (or #s, #m, #h)
introduces a this many (s)econds, (m)inutes, or (h)ours between successive
commands to nodes to prevent overutilization of resources. ie between
initiating a 'yum -y upgrade' to prevent all the nodes from hitting a
local repository simultaneously. If no s|m|h is given, seconds are assumed.
Fractions (0.01h) are fine.
--listgroup=[GROUP,GROUP..] (GROUPs from config file)
If no GROUP specified, dumps IP #s for ALL GROUPS.
This option does not require a 'remote command' and ignores it
if given.
--fork (default) Sends 'remote command' to all nodes in parallel
and saves output from nodes into a dated subdir for later perusal.
If you submit a command to run in parallel, it must run to completion
without intervention. ie: to install on a CentOS node, the 'yum install'
command must have the '-y' flag as well: 'yum install -y' to signify
that 'Y' is assumed to be the answer to all questions.
If you use the --fork command (as above)), instead of producing the
stdout/err immediately, a new subdir will be created with the name
of the format:
REMOTE_CMD-(20 chars of the command)-time_date
and the output for each node will be directed into a separate file
named for the IP number or hostname (whichever the input spec was).
--nofork .... Execs 'remote command' serially to each specified node and
emits the output from each node as it's generated. If executed with
this option, it will produce a list of stanzas corresponding to the
nodes requested:
--------------------------------
a64-101 [192.168.0.10]:
<output from the command>
a64-102 [192.168.0.11]:
<output from the command>
--------------------------------
--script .... causes the command to run without any STDOUT until it emits
the result dir at the end of the run. The usual STDOUT is saved as:
<result_dir>/LOG.
--debug ..... causes voluminous debug messages to spew forth
10. Some real-world examples
To cause cf to dump its help file into the less pager
$ clusterfork -h
Have cf read the alternative config file ./this_cf_file and list the groups that are defined there.
clusterfork --config=./this_cf_file --listgroup
Have cf read the default config file and target the group CLAWS with the command ls -lSh
$ clusterfork --target=CLAWS 'ls -lSh'
Check the memory error counts for the nodes 192.168.1.15 thru 192.168.1.75 except 192.168.1.66
$ clusterfork --target=192.18.1.[15:75 -66] \ 'cd /sys/devices/system/edac/mc && grep [0-9]* mc*/csrow*/[cu]e_count'
Tell the nodes in the group ALL_ADC to send a single ping to the login node
$ clusterfork --target=ALL_ADC 'ping -c 1 bduc-login'
Ask the nodes [10.255.78.12 to 10.255.78.45] and [10.255.35.101 to 10.255.35.165] to dump the catalog of their installed packages.
clusterfork --target='10.255.78.[12:45] 10.255.35.[101:165]' 'dpkg -l'
Ask the nodes in the ADC_2X group to /serially/ dump their hardware memory configuration
$ sudo clusterfork --target=ADC_2X --nofork 'lshw -short -class memory'
Do all the nodes have libXp.so.6?
$ cf --target=QHOST 'locate libXp.so.6
You can use hostnames as well as IP #s:
$ sudo clusterfork --target=a64-[0005:0078 -22 -52 -57].bduc 'ps aux |grep gromacs'
Using a script to specify the list of nodes to target:
$ sudo clusterfork --target=QHOST 'yum install -y tree'
In the above example, the ~/.clusterforkrc file has the following line:
QHOST = "SCRIPT:qhost |grep a64 | grep -v ' - ' | scut --c1=0 | perl -e 's/\\n/ /gi' -p"
which calls the SGE utility qhost, filters the output and stream-edits the STDOUT to create a space-delimited list that can be processed by cf.
11. Output
When cf is executed in forking mode, it waits for all the slave processes to finish, then allows you to view both the Summary and the full results, which are also written to the newly created directory named with a combination of the command, the date and the time:
$ clusterfork.pl --target=QHOST 'ls -lSh *gz'
INFO: Creating dir [REMOTE_CMD-ls--lSh--gz-15.28.09_2012-01-01]....success
======================================================
Processing [QHOST]
======================================================
Host: a64-001 [10.255.89.5]:
Host: a64-002 [10.255.89.6]:
Host: a64-003 [10.255.89.7]:
Host: a64-004 [10.255.89.8]:
Host: a64-005 [10.255.89.9]:
Host: a64-006 [10.255.89.10]:
...
Host: a64-182 [10.255.78.91]:
Host: a64-183 [10.255.78.93]:
==========================================
# of processes at start: [118]
Waiting for [41] hosts @ [0] sec:
a64-142 a64-143 a64-144 a64-145 a64-146 a64-147 a64-148 a64-149 a64-150 a64-151 a64-152
a64-153 a64-154 a64-155 a64-156 a64-157 a64-158 a64-159 a64-160 a64-161 a64-162 a64-163
a64-164 a64-166 a64-167 a64-168 a64-169 a64-170 a64-171 a64-172 a64-173 a64-174 a64-175
a64-176 a64-177 a64-178 a64-179 a64-180 a64-181 a64-182 a64-183
Waiting for [0] hosts @ [2] sec:
... All slave processes finished!
You can find the results of your command in the dir
[ REMOTE_CMD-ls--lSh--gz-15.28.09_2012-01-01 ]
(View Summary file in 'less')
Summary of contents for files in /home/hmangala/cf/REMOTE_CMD-ls--lSh--gz-16.46.56_2012-08-07
Each line denotes MD5 identical output; wordcount shows similarity
Command: [ls -lSh *gz]
========================================================================
line / word / chars | # | hosts ->
14 126 1040 107 a64-001 a64-002 a64-003 a64-004 a64-005 a64-006 a64-007 a64-008 ...
14 126 1040 25 n101 n102 n103 n104 n105 n106 n107 n108 n109 n110 n111 n112 n113 ...
14 112 1096 10 claw1 claw10 claw2 claw3 claw4 claw5 claw6 claw7 claw8 claw9
If n, it drops you to the shell prompt. If Enter or y, it will present the directory in Midnight Commander. Depending on your configuration, you should be able to view the files simply by highlight them with the cursor.
In the above case, because of the shared dir structure, the Summary shows that the result is identical on all nodes but the ls format differences between the CentOS, Ubuntu, and Debian nodes create are picked up even when the wordcounts are identical.
In the case below, there’s a lot of zero-length files, which can be deleted before you view them individually.
Summary of contents for files in /home/hmangala/cf/REMOTE_CMD-df--h--grep--56789-.-16.43.14_2012-08-07
Each line denotes MD5-identical output; wordcount shows similarity
Command: [df -h |grep [56789].%]
========================================================================
line / word / chars | # | hosts ->
1 6 54 1 a64-182
0 0 0 110 a64-001 a64-002 a64-003 a64-004 a64-005 a64-006 a64-007 ...
1 6 49 1 claw6
1 6 51 1 claw10
1 6 46 1 a64-121
1 6 46 1 a64-109
1 6 46 1 claw1
2 11 112 25 n101 n102 n103 n104 n105 n106 n107 n108 n109 n110 n111 ...
1 6 46 1 a64-035
The latest versions of clusterfork now symlink the MD5-identical outputs into dirs that contain ONLY those node names that are identical.
The last line of the Summary file lists nodes that are unresponsive by ping, so that you can add them to the IGNORE group in the .clusterforkrc file.
This last option of the clusterfork analysis allows you to view the results in Midnight Commander (aka mc). The above results shown in mc look like this:
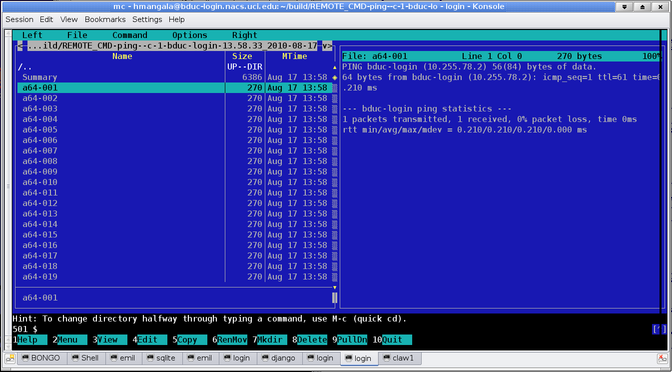
12. Known Problems
clusterfork is a fairly new program and while it works pretty well, there are some known or possible problems, mostly having to do with regular expressions.
-
regular expressions passed as part of the remote command may suffer in the ssh to shell translation and be garbled on the remote end. I’ve been using it in production for about 2 years and have found a few (corrected) problems but it’s a consideration, especially when the remote command is complicated.
-
the 1st 20 characters of the commandline are used as part of the directory name and regular expressions included as part of those 20 characters may sometimes be garbled into impossible dir names which are rejected by the OS. An error message should be emitted if this happens and I’m trying to catch and retranslate these regexes.
-
if the Linux distro from which you issue the cf command aliases /bin/sh to dash instead of bash (as do most recent Ubuntu-derived distros), the redirection of the output when using the default fork behavior will be odd. It will not redirect to the usual files, but will be written to the screen in one blurb. The dash/bash weirdness also contributes other instabilities, so I usually change this so that /bin/sh → /bin/bash. If too many people complain, I’ll add some work-around code to the script.
-
in versions prior to 1.55, if the host/IP specification included a negation of the last number in the series, it would write an undef in the last position. ie: in the spec a64-[001:040 -012 -013 -040], 040 would be undef’ed leading to an warning when running and the last host not being processed (but since it was negated, it wasn’t meant to be processed anyway.)
PLEASE let me know if you run into any of these regex problems or other problems.
13. Versions & Changes
-
1.82 - (06-16-16) log unresponsive nodes to Summary file.
-
1.81 - (04-19-16) add md5 checksum filtering of output files into identical-content dirs and symlink the output file names to the correct ones.
-
1.80 - (2-10-14) added filters to strip annoying spurious errors from out put, especially "Warning: No xauth data; using fake authentication data for X11 forwarding." Include the filter string as part of the config file, not the code.
-
1.79 - (11-08-13) added --skip so can skip processing of a node that has been used as a guinea pig and now no longer needs to be processed fixed IGNORE group handling so that can use either IP# or hostname fixed some doc errors
-
1.78 - (09-12-13) should only show scrolling changes once the list has changed from 1st list. so if there are 22 hosts in list, the scroll shouldn’t start until the list drops to 21
-
1.77 - (06-14-2013) cosmetic changes; narrow output, short-circuit last 2 s wait, rename output dir from REMOTE-CMD to CF'.
-
1.76 - (05.1.13) FIXED: complains about IP#-based host specs, so have to make sure it can take specs like 10.3.22.[4:45] without barfing. FIXED: handles unresolved IP#s better - times out in 1s waiting for ping & continues. FIXED: characters like < & > fail. FIXED: # hosts left stays at 0 instead of tracking the # correctly.
-
1.75 - (11.29.12) add final timing line to LOG so can grep for it more easily.
-
1.74 - (10.15.12) shortcut final pointless 2s cycle at end
-
1.73 - (10.04.12) set a timeout for --script version to prevent infinite hanging.
-
1.72 - (08.20.12) small mod to delete empty files before asking to view them.
-
1.71 - (08.17.12) don’t even bother including zero-len results (they’re empty fer gadsakes).
-
1.70 - (08.07.12) optionally delete zero-len files before viewing in mc for efficiency. The summary still contains the list of zero-len files if you need them.
-
1.69 - (07.11.12) fixed small bug in specifying multiple hosts in the IPRANGE stanzas and updated initial .clusterforkrc file for better examples.
-
1.68 - (05.03.12) added config to specify which xterm thingy you want to use. Set as gnome-terminal to begin with. change it to xterm, terminator, konsole, etc. Also, fork the $XTERM so that it leaves the current term able to do something else.
-
1.67 - (04.23.12) added --script option to do everything silently and NO query to see results. ie: "cf --script" ends by returning the results dir so that the rest of the script can process the results.
-
1.66 - (01.24.12) corrected subtle PID sed error that led to correct number but empty host list (PIDs sometimes listed with leading space which confused cut)
-
1.65 - (01.20.12) added $RESULTS_DIR to write all results.
-
1.64 - (01.01.12) added hostname tracking to ID hung or trailing hosts.
-
1.63 - (12.28.11) fix ; delimited IPRANGES bug, single hostname problem/process .
-
1.62 - (12.19.11) added --delay to slow the speed of execution of successive commands.
-
1.61 - redirect STDERR into file along with STDOUT.
-
1.60 - fixed a few more oddball characters that bugger up the dir creation.
-
1.59 - fixed system redirection syntax to be more robust(?) across systems.
-
1.58 - added --hosts=[quoted space-delimited hostnames] option to process a few random hosts
-
1.57 - fixed bug in code that searches for alt config file. Now only writes the local config file if there is none AND there’s no alt config file specified.
-
1.56 - fixed bug introduced in 1.55 that would end the run prematurely - wouldn’t get to last number in series; typical off-by-one stupidity.
-
1.55 - fixed bug where if last number in a series was negated, array would overrun, generating an undefined value. (ie a64-[001:040 -012 -013 -040])
-
1.54 - handled single hostname spec in .clusterfork
-
1.52 - added PID tracking and process waiting
-
1.51 - fixed $padlen for digits that did not have a leading 0
14. Alternatives
There are existing tools that do something similar:
-
pdsh - pdsh is the nicest (and coincidentally, most like cf). It’s compiled C and so runs very fast and handles the additional instances as threads instead of extra processes, so it’s better behaved when trying to kill off an in-process execution. It also supports module plug-ins if you need that. It has a host range specification that’s almost as slick as cf’s, but it lacks the results compilation/collation function of cf and the ability to add groups together. But a very nice utility, under ongoing development.
-
pssh - pssh is a very nice set of tools written in Python. It’s fairly mature and has been packaged nicely. It can use a configuration file (and in fact doesn’t allow IP range specification from the commandline), and it can write the results to a dir (but doesn’t write a summary or allow in-line viewing. A nice example is described here. It doesn’t allow as easy a IP range specification, nor grouping as clusterfork. It also is a set of tools rather than one. But since it is available via both RPM and deb, it is very convenient to install. If you’re using pssh and are familiar with it, I’d suggest staying with it.
-
ClusterIt - this is a fairly large hammer when all I wanted was to send commands to a set of nodes. ClusterIt is writ in C, for speed supposedly, tho what it’s doing is just issuing commands so speed of execution shouldn’t be an issue. It’s also trying to be a scheduling tool which complicates the core functionality of what should be a pretty simple tool.
-
clusterssh aka cssh is a similar tool (but requires tcl/tk). As such it has some advantages - can set up hosts and de/select hosts via mouse, but you interact with the targets via 1 xterm per host, hardly an efficient use of your desktop.
-
gexec (now part of the ganglia project) is both considerably more complex and (possibly) more capable than cf. It requires the installation of authd and the ganglia system. By comparison, cf installs its own config file on 1st run and then is fairly independent. If you’re forking the commands over several thousand nodes instead of a few hundred, gexec may be worth the extra effort.
-
tentakel; the home page is down at the moment. Here’s a description tho. Very short python script that does what clusterfork did in version 1 when it was still a bash script.
-
rgang sounds a lot like clusterfork and can apparently use a tree-structure to spawn copies of itself so that there are multiple copies of itself spawning multiple copies of itself. If this sounds like a good idea, you should contact Fermilab.
None of the above utils has 'cf’s very slick host range specification tho… :)
15. Latest Version
The latest version of the clusterfork code and documentation will always be found here.